While searching for new Higgs bosons the CMS experiment at the Large Hadron Collider (LHC) may have just found a surprise. They have observed an excess of events that look to be a new particle, and are reporting high statistical evidence for their claim. The only question is what exactly is this new particle?
The search was initially designed to look for new, heavier, versions of the Higgs boson decaying to a top quark and an anti-top quark. Its well known that the Higgs boson of the Standard Model, discovered jointly by ATLAS and CMS in 2012, underlies the mechanism which gives all fundamental particles their masses. The Higgs boson itself interacts with particles in proportion to their mass, preferring heavier particles over lighter ones. It therefore interacts the most strongly with the heaviest known fundamental particle, the top quark, which has a mass of ~173 GeV. The Higgs boson itself only has a bass of 125 GeV, meaning conservation of energy dictates it can’t decay into a top quark-antiquark pair.
However many theories of physics beyond the the Standard Model predict additional Higgs bosons, heavier cousins of the current one. If these new heavy Higgs bosons had a mass larger than 350 GeV, they would likely decay to a top quark-antiquark pair quite often. CMS therefore was analyzed its data searching for this signature, hoping to find signs of a new Higgs boson. To do so, they had scrutinize very carefully the known production of top quark-antiquark pairs, which are produced copiously at the LHC from other processes. If a new particle was being produced and decaying to top quarks, the mass of the new particle would give the top quarks a characteristic energy. One key sign of a new particle would therefore be an excess of top quark-antiquark events at a particular energy, corresponding to the mass of the new particle.
When CMS scrutinized their data looking for such an excess they found one. But curiously right ~350 GeV, the minimum energy required to produce the top quark-antiquark pair. It would be quite the coincidence for a new particle to show up right at this minimum threshold, which made CMS consider alternative possibilities.
A comparison of the observed CMS data and their estimate of backgrounds as a function of the invariant mass of the top quark antiquark system. CMS observes an excess of events at ~350 GeV, which is well fit with a toponium model (red line).
One unorthodox explanation that seems to fit the bill is ‘toponium’, a short lived bound state of the top quark-antiquark pair is being formed. Toponium would be the heaviest version of ‘quarkonia’ we have seen, bound states of quark antiquark pairs that form bound states similar to atoms. We have observed and measured quarkonia states of the other quarks for decades, however it was long thought that the top quark, whose large mass causes it to decay in just 10^(-25) seconds, would decay too quickly to create observable bound state effects at a hadron collider. Toponium production would happen most often if the top quarks were produced just at the energy threshold, such that they don’t any extra energy. These low energy top quarks would spend more time close to each other than normal, rather than immediately flying away, so they could have time to briefly form a toponium state before decaying. However, once small hints of intriguing excesses started appearing in LHC analyses, updated calculations in the last few years suggested that perhaps such an effect could be observable.
These calculations are approximate, and more work is still being done to refine them. But the preliminary predictions they give for the properties of toponium seem to match well with what CMS is seeing, both in terms of the rate of toponium production and the quantum properties of the toponium state (spin and parity).
Still CMS is being cautious before claiming a discovery of toponium. They claim observation of an ‘excess at the top quark pair production threshold’ which is consistent with toponium. However given the limited present data and incomplete theoretical models of toponium, they cannot rule out that the excess they are seeing is coming from a new Higgs-like particle.
CMS measurement tries to disentangle the quantum properties of the observed excess. The x-axis shows the estimated rate of production a ‘pseudoscalar’ particle producing the excess. The y-axis shows a similar estimate for a ‘scalar’ particle. The allowed region for the scalar still includes zero, while the zero pseudoscalar hypothesis is clearly excluded at larger than 5 standard deviations.
Further work will be needed to develop improved theoretical models of toponium, and detailed studies from CMS assessing the properties of their observed excess. The excess will also need confirmation from CMS’s rival LHC experiment, ATLAS, to ensure it has not merely made a mistake in its analysis.
However, the smart money would say this very likely looks like toponium. Which, while not signaling the long sought overthrow of the standard model, would be an unexpected and cool surprise from the LHC. Understanding the properties of this previously-thought-impossible quasiparticle will spawn much fruitful research in the years to come. Physicists love a surprise!
Discloure: The author is a member of the CMS collaboration but did not directly work on this analysis
Erratum 4/15/2025 : The article was updated to clarify that in the theory literature prior to the LHC toponium was thought possible to form, just that it was thought to be too small an effect to be observable. The article previously incorrectly stated it had been previously thought impossible to form
This is the second part of our coverage of the P5 report and its implications for particle physics. To read the first part, click here
One of the thorniest questions in particle physics is ‘What comes after the LHC?’. This was one of the areas people were most uncertain what the P5 report would say. Globally, the field is trying to decide what to do once the LHC winds down in ~2040 While the LHC is scheduled to get an upgrade in the latter half of the decade and run until the end of the 2030’s, the field must start planning now for what comes next. For better or worse, big smash-y things seem to capture a lot of public interest, so the debate over what large collider project to build has gotten heated. Even Elon Musk is tweeting (X-ing?) memes about it.
Famously, the US’s last large accelerator project, the Superconducting Super Collider (SSC), was cancelled in the ’90s partway through its construction. The LHC’s construction itself often faced perilous funding situations, and required a CERN to make the unprecedented move of taking a loan to pay for its construction. So no one takes for granted that future large collider projects will ultimately come to fruition.
Desert or Discovery?
When debating what comes next, dashed hopes of LHC discoveries are top of mind. The LHC experiments were primarily designed to search for the Higgs boson, which they successfully found in 2012. However, many had predicted (perhaps over-confidently) it would also discover a slew of other particles, like those from supersymmetry or those heralding extra-dimensions of spacetime. These predictions stemmed from a favored principle of nature called ‘naturalness’ which argued additional particles nearby in energy to the Higgs were needed to keep its mass at a reasonable value. While there is still much LHC data to analyze, many searches for these particles have been performed so far and no signs of these particles have been seen.
These null results led to some soul-searching within particle physics. The motivations behind the ‘naturalness’ principle that said the Higgs had to be accompanied by other particles has been questioned within the field, and in New York Times op-eds.
No one questions that deep mysteries like the origins of dark matter, matter anti-matter asymmetry, and neutrino masses, remain. But with the Higgs filling in the last piece of the Standard Model, some worry that answers to these questions in the form of new particles may only exist at energy scales entirely out of the reach of human technology. If true, future colliders would have no hope of
A diagram of the particles of the Standard Model laid out as a function of energy. The LHC and other experiments have probed up to around 10^3 GeV, and found all the particles of the Standard Model. Some worry new particles may only exist at the extremely high energies of the Planck or GUT energy scales. This would imply a large large ‘desert’ in energy, many orders of magnitude in which no new particles exist. Figure adapted from here
The situation being faced now is qualitatively different than the pre-LHC era. Prior to the LHC turning on, ‘no lose theorems’, based on the mathematical consistency of the Standard Model, meant that it had to discover the Higgs or some other new particle like it. This made the justification for its construction as bullet-proof as one can get in science; a guaranteed Nobel prize discovery. But now with the last piece of the Standard Model filled in, there are no more free wins; guarantees of the Standard Model’s breakdown don’t occur until energy scales we would need solar-system sized colliders to probe. Now, like all other fields of science, we cannot predict what discoveries we may find with future collider experiments.
Still, optimists hope, and have their reasons to believe, that nature may not be so unkind as to hide its secrets behind walls so far outside our ability to climb. There are compelling models of dark matter that live just outside the energy reach of the LHC, and predict rates too low for direct detection experiments, but would be definitely discovered or ruled out by high energy colliders. The nature of the ‘phase transition’ that occurred in the very early universe, which may explain the prevalence of matter over anti-matter, can also be answered. There are also a slew ofexperimental ‘hints‘, all of which have significant question marks, but could point to new particles within the reach of a future collider.
Many also just advocate for building a future machine to study nature itself, with less emphasis on discovering new particles. They argue that even if we only further confirm the Standard Model, it is a worthwhile endeavor. Though we calculate Standard Model predictions for high energies, unless they are tested in a future collider we will not ‘know’ how if nature actually works like this until we test it in those regimes. They argue this is a fundamental part of the scientific process, and should not be abandoned so easily. Chief among the untested predictions are those surrounding the Higgs boson. The Higgs is a central somewhat mysterious piece of the Standard Model but is difficult to measure precisely in the noisy environment of the LHC. Future colliders would allow us to study it with much better precision, and verify whether it behaves as the Standard Model predicts or not.
Projects
These theoretical debates directly inform what colliders are being proposed and what their scientific case is.
Many are advocating for a “Higgs factory”, a collider of based on clean electron-positron collisions that could be used to study the Higgs in much more detail than the messy proton collisions of the LHC. Such a machine would be sensitive to subtle deviations of Higgs behavior from Standard Model predictions. Such deviations could come from the quantum effects of heavy, yet-undiscovered particles interacting with the Higgs. However, to determine what particles are causing those deviations, its likely one would need a new ‘discovery’ machine which has high enough energy to produce them.
Among the Higgs factory options are the International Linear Collider, a proposed 20km linear machine which would be hosted in Japan. ILC designs have been ‘ready to go’ for the last 10 years but the Japanese government has repeated waffled on whether to approve the project. Sitting in limbo for this long has led to many being pessimistic about the projects future, but certainly many in the global community would be ecstatic to work on such a machine if it was approved.
Designs for the ILC have been ready for nearly a decade, but its unclear if it will receive the greenlight from the Japanese government. Image source
Alternatively, some in the US have proposed building a linear collider based on a ‘cool copper’ cavities (C3) rather than the standard super conducting ones. These copper cavities can achieve more acceleration per meter than the standard super conducting ones, meaning a linear Higgs factory could be constructed with a reduced 8km footprint. A more compact design can significantly cut down on infrastructure costs that governments usually don’t like to use their science funding on. Advocates had proposed it as a cost-effective Higgs factory option, whose small footprint means it could potentially hosted in the US.
The Future-Circular-Collider (FCC), CERN’s successor to the LHC, would kill both birds with one extremely long stone. Similar to the progression from LEP to the LHC, this new proposed 90km collider would run as Higgs factory using electron-positron collisions starting in 2045 before eventually switching to a ~90 TeV proton-proton collider starting in ~2075.
Designs for the massive 90km FCC ring surrounding Geneva
Such a machine would undoubtably answer many of the important questions in particle physics, however many have concerns about the huge infrastructure costs needed to dig such a massive tunnel and the extremely long timescale before direct discoveries could be made. Most of the current field would not be around 50 years from now to see what such a machine finds. The Future-Circular-Collider (FCC), CERN’s successor to the LHC, would kill both birds with one extremely long stone. Similar to the progression from LEP to the LHC, this new proposed 90km collider would run as Higgs factory using electron-positron collisions starting in 2045 before eventually switching to a ~90 TeV proton-proton collider starting in ~2075. Such a machine would undoubtably answer many of the important questions in particle physics, however many have concerns about the extremely long timescale before direct discoveries could be made. Most of the current field would not be around 50 years from now to see what such a machine finds. The FCC is also facing competition as Chinese physicists have proposed a very similar design (CEPC) which could potentially start construction much earlier.
During the snowmass process many in the US starting pushing for an ambitious alternative. They advocated a new type of machine that collides muons, the heavier cousin of electrons. A muon collider could reach the high energies of a discovery machine while also maintaining a clean environment that Higgs measurements can be performed in. However, muons are unstable, and collecting enough of them into formation to form a beam before they decay is a difficult task which has not been done before. The group of dedicated enthusiasts designed t-shirts and Twitter memes to capture the excitement of the community. While everyone agrees such a machine would be amazing, the key technologies necessary for such a collider are less developed than those of electron-positron and proton colliders. However, if the necessary technological hurdles could be overcome, such a machine could turn on decades before the planned proton-proton run of the FCC. It can also presents a much more compact design, at only 10km circumfrence, roughly three times smaller than the LHC. Advocates are particularly excited that this would allow it to be built within the site of Fermilab, the US’s flagship particle physics lab, which would represent a return to collider prominence for the US.
A proposed design for a muon collider. It relies on ambitious new technologies, but could potentially deliver similar physics to the FCC decades sooner and with a ten times smaller footprint. Source
Deliberation & Decision
This plethora of collider options, each coming with a very different vision of the field in 25 years time led to many contentious debates in the community. The extremely long timescales of these projects led to discussions of human lifespans, mortality and legacy being much more being much more prominent than usual scientific discourse.
Ultimately the P5 recommendation walked a fine line through these issues. Their most definitive decision was to recommend against a Higgs factor being hosted in the US, a significant blow to C3 advocates. The panel did recommend US support for any international Higgs factories which come to fruition, at a level ‘commensurate’ with US support for the LHC. What exactly ‘comensurate’ means in this context I’m sure will be debated in the coming years.
However, the big story to many was the panel’s endorsement of the muon collider’s vision. While recognizing the scientific hurdles that would need to be overcome, they called the possibility of muon collider hosted in the US a scientific ‘muon shot‘, that would reap huge gains. They therefore recommended funding for R&D towards they key technological hurdles that need to be addressed.
Because the situation is unclear on both the muon front and international Higgs factory plans, they recommended a follow up panel to convene later this decade when key aspects have clarified. While nothing was decided, many in the muon collider community took the report as a huge positive sign. While just a few years ago many dismissed talk of such a collider as fantastical, now a real path towards its construction has been laid down.
Hitoshi Murayama, chair of the P5 committee, cuts into a ‘Shoot for the Muon’ cake next to a smiling Lia Merminga, the director of Fermilab. Source
While the P5 report is only one step along the path to a future collider, it was an important one. Eyes will now turn towards reports from the different collider advocates. CERN’s FCC ‘feasibility study’, updates around the CEPC and, the International Muon Collider Collaboration detailed design report are all expected in the next few years. These reports will set up the showdown later this decade where concrete funding decisions will be made.
For those interested the full report as well as executive summaries of different areas can be found on the P5 website. Members of the US particle physics community are also encouraged to sign the petition endorsing the recommendations here.
Every year since 1966, particle physicists have gathered in the Alps to unveil and discuss their most important results of the year (and to ski). This year I had the privilege to attend the Moriond QCD session so I thought I would post a recap here. It was a packed agenda spanning 6 days of talks, and featured a lot of great results over many different areas of particle physics, so I’ll have to stick to the highlights here.
FASER Observes First Collider Neutrinos
Perhaps the most exciting result of Moriond came from the FASER experiment, a small detector recently installed in the LHC tunnel downstream from the ATLAS collision point. They announced the first ever observation of neutrinos produced in a collider. Neutrinos are produced all the time in LHC collisions, but because they very rarely interact, and current experiments were not designed to look for them, no one had ever actually observed them in a detector until now. Based on data collected during collisions from last year, FASER observed 153 candidate neutrino events, with a negligible amount of predicted backgrounds; an unmistakable observation.
A neutrino candidate in the FASER emulsion detector. Source
This first observation opens the door for studying the copious high energy neutrinos produced in colliders, which sit in an energy range currently unprobed by other neutrino experiments. The FASER experiment is still very new, so expect more exciting results from them as they continue to analyze their data. A first search for dark photons was also released which should continue to improve with more luminosity. On the neutrino side, they have yet to release full results based on data from their emulsion detector which will allow them to study electron and tau neutrinos in addition to the muon neutrinos this first result is based on.
New ATLAS and CMS Results
The biggest result from the general purpose LHC experiments was ATLAS and CMS bothannouncing that they have observed the simultaneous production of 4 top quarks. This is one of the rarest Standard Model processes ever observed, occurring a thousand times less frequently than a Higgs being produced. Now that it has been observed the two experiments will use Run-3 data to study the process in more detail in order to look for signs of new physics.
Candidate 4 top events from ATLAS (left) and CMS (right).
ATLAS also unveiled an updated measurement of the mass of the W boson. Since CDF announced its measurement last year, and found a value in tension with the Standard Model at ~7-sigma, further W mass measurements have become very important. This ATLAS result was actually a reanalysis of their previous measurement, with improved PDF’s and statistical methods. Though still not as precise as the CDF measurement, these improvements shrunk their errors slightly (from 19 to 16 MeV). The ATLAS measurement reports a value of the W mass in very good agreement with the Standard Model, and approximately 4-sigma in tension with the CDF value. These measurements are very complex, and work is going to be needed to clarify the situation.
CMS had an intriguing excess (2.8-sigma global) in a search for a Higgs-like particle decaying into an electron and muon. This kind of ‘flavor violating’ decay would be a clear indication of physics beyond the Standard Model. Unfortunately it does not seem like ATLAS has any similar excess in their data.
Status of Flavor Anomalies
At the end of 2022, LHCb announced that the golden channel of the flavor anomalies, the R(K) anomaly, had gone away upon further analysis. Many of the flavor physics talks at Moriond seemed to be dealing with this aftermath.
Of the remaining flavor anomalies, R(D), a ratio describing the decay rates of B mesons in final states with D mesons and taus versus D mesons plus muons or electrons, has still been attracting interest. LHCb unveiled a new measurement that focused on hadronically taus and found a value that agreed with the Standard Model prediction. However this new measurement had larger error bars than others so it only brought down the world average slightly. The deviation currently sits at around 3-sigma.
A summary plot showing all the measurements of R(D) and R(D*). The newest LHCb measurement is shown in the red band / error bar on the left. The world average still shows a 3-sigma deviation to the SM prediction
An interesting theory talk pointed out that essentially any new physics which would produce a deviation in R(D) should also produce a deviation in another lepton flavor ratio, R(Λc), because it features the same b->clv transition. However LHCb’s recent measurement of R(Λc) actually found a small deviation in the opposite direction as R(D). The two results are only incompatible at the ~1.5-sigma level for now, but it’s something to continue to keep an eye on if you are following the flavor anomaly saga.
It was nice to see that the newish Belle II experiment is now producing some very nice physics results. The highlight of which was a world-best measurement of the mass of the tau lepton. Look out for more nice Belle II results as they ramp up their luminosity, and hopefully they can weigh in on the R(D) anomaly soon.
A fit to the invariant mass the visible decay products of the tau lepton, used to determine its intrinsic mass. An impressive show of precision from Belle II
Theory Pushes for Precision
The focus of much of the theory talks was about trying to advance our precision in predictions of standard model physics. This ‘bread and butter’ physics is sometimes overlooked in scientific press, but is an absolutely crucial part of the particle physics ecosystem. As experiments reach better and better precision, improved theory calculations are required to accurately model backgrounds, predict signals, and have precise standard model predictions to compare to so that deviations can be spotted. Nice results in this area included evidence for an intrinsic amount of charm quarks inside the proton from the NNPDF collaboration, very precise extraction of CKM matrix elements by using lattice QCD, and twodifferent proposals for dealing with tricky aspects regarding the ‘flavor’ of QCD jets.
Final Thoughts
Those were all the results that stuck out to me. But this is of course a very biased sampling! I am not qualified enough to point out the highlights of the heavy ion sessions or much of the theory presentations. For a more comprehensive overview, I recommend checking out the slides for the excellent experimental and theoretical summary talks. Additionally there was the Moriond Electroweak conference that happened the week before the QCD one, which covers many of the same topics but includes neutrino physics results and dark matter direct detection. Overall it was a very enjoyable conference and really showcased the vibrancy of the field!
When students first learn quantum field theory, the mathematical language the underpins the behavior of elementary particles, they start with the simplest possible interaction you can write down : a particle with no spin and no charge scattering off another copy of itself. One then eventually moves on to the more complicated interactions that describe the behavior of fundamental particles of the Standard Model. They may quickly forget this simplified interaction as a unrealistic toy example, greatly simplified compared to the complexity the real world. Though most interactions that underpin particle physics are indeed quite a bit more complicated, nature does hold a special place for simplicity. This barebones interaction is predicted to occur in exactly one scenario : a Higgs boson scattering off itself. And one of the next big targets for particle physics is to try and observe it.
A Feynman diagram of the simplest possible interaction in quantum field theory, a spin-zero particle interacting with itself.
The Higgs is the only particle without spin in the Standard Model, and the only one that doesn’t carry any type of charge. So even though particles such as gluons can interact with other gluons, its never two of the same kind of gluons (the two interacting gluons will always carry different color charges). The Higgs is the only one that can have this ‘simplest’ form of self-interaction. Prominent theorist Nima Arkani-Hamed has said that the thought of observing this “simplest possible interaction in nature gives [him] goosebumps“.
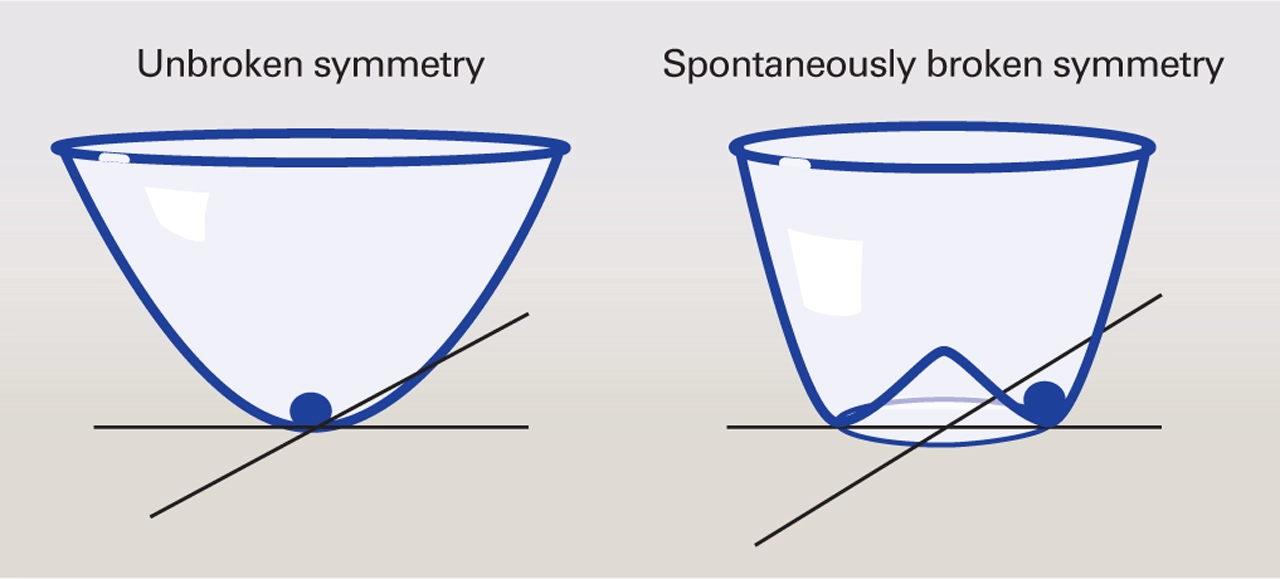
But more than being interesting for its simplicity, this self-interaction of the Higgs underlies a crucial piece of the Standard Model: the story of how particles got their mass. The Standard Model tells us that the reason all fundamental particles have mass is their interaction with the Higgs field. Every particle’s mass is proportional to the strength of the Higgs field. The fact that particles have any mass at all is tied to the fact that the lowest energy state of the Higgs field is at a non-zero value. According to the Standard Model, early in the universe’s history when the temperature were much higher, the Higgs potential had a different shape, with its lowest energy state at field value of zero. At this point all the particles we know about were massless. As the universe cooled the shape of the Higgs potential morphed into a ‘wine bottle’ shape, and the Higgs field moved into the new minimum at non-zero value where it sits today. The symmetry of the initial state, in which the Higgs was at the center of its potential, was ‘spontaneously broken’ as its new minimum, at a location away from the center, breaks the rotation symmetry of the potential. Spontaneous symmetry breaking is a very deep theoretical idea that shows up not just in particle physics but in exotic phases of matter as well (eg superconductors).
A diagram showing the ‘unbroken’ Higgs potential in the very early universe (left) and the ‘wine bottle’ shape it has today (right). When the Higgs at the center of its potential it has a rotational symmetry, there are no preferred directions. But once it finds it new minimum that symmetry is broken. The Higgs now sits at a particular field value away from the center and a preferred direction exists in the system.
This fantastical story of how particle’s gained their masses, one of the crown jewels of the Standard Model, has not yet been confirmed experimentally. So far we have studied the Higgs’s interactions with other particles, and started to confirm the story that it couples to particles in proportion to their mass. But to confirm this story of symmetry breaking we will to need to study the shape of the Higgs’s potential, which we can probe only through its self-interactions. Many theories of physics beyond the Standard Model, particularly those that attempt explain how the universe ended up with so much matter and very little anti-matter, predict modifications to the shape of this potential, further strengthening the importance of this measurement.
Unfortunately observing the Higgs interacting with itself and thus measuring the shape of its potential will be no easy feat. The key way to observe the Higgs’s self-interaction is to look for a single Higgs boson splitting into two. Unfortunately in the Standard Model additional processes that can produce two Higgs bosons quantum mechanically interfere with the Higgs self interaction process which produces two Higgs bosons, leading to a reduced production rate. It is expected that a Higgs boson scattering off itself occurs around 1000 times less often than the already rare processes which produce a single Higgs boson. A few years ago it was projected that by the end of the LHC’s run (with 20 times more data collected than is available today), we may barely be able to observe the Higgs’s self-interaction by combining data from both the major experiments at the LHC (ATLAS and CMS).
Fortunately, thanks to sophisticated new data analysis techniques, LHC experimentalists are currently significantly outpacing the projected sensitivity. In particular, powerful new machine learning methods have allowed physicists to cut away background events mimicking the di-Higgs signal much more than was previously thought possible. Because each of the two Higgs bosons can decay in a variety of ways, the best sensitivity will be obtained by combining multiple different ‘channels’ targeting different decay modes. It is therefore going to take a village of experimentalists each working hard to improve the sensitivity in various different channels to produce the final measurement. However with the current data set, the sensitivity is still a factor of a few away from the Standard Model prediction. Any signs of this process are only expected to come after the LHC gets an upgrade to its collision rate a few years from now.
Current experimental limits on the simultaneous production of two Higgs bosons, a process sensitive to the Higgs’s self-interaction, from ATLAS (left) and CMS (right). The predicted rate from the Standard Model is shown in red in each plot while the current sensitivity is shown with the black lines. This process is searched for in a variety of different decay modes of the Higgs (various rows on each plot). The combined sensitivity across all decay modes for each experiment allows them currently to rule out the production of two Higgs bosons at 3-4 times the rate predicted by the Standard Model. With more data collected both experiments will gain sensitivity to the range predicted by the Standard Model.
While experimentalists will work as hard as they can to study this process at the LHC, to perform a precision measurement of it, and really confirm the ‘wine bottle’ shape of the potential, its likely a new collider will be needed. Studying this process in detail is one of the main motivations to build a new high energy collider, with the current leading candidates being an even bigger proton-proton collider to succeed the LHC or a new type of high energy muon collider.
A depiction of our current uncertainty on the shape of the Higgs potential (center), our expected uncertainty at the end of the LHC (top right) and the projected uncertainty a new muon collider could achieve (bottom right). The Standard Model expectation is the tan line and the brown band shows the experimental uncertainty. Adapted from Nathaniel Craig’s talkhere
The quest to study nature’s simplest interaction will likely span several decades. But this long journey gives particle physicists a roadmap for the future, and a treasure worth traveling great lengths for.
Just before the 2022 holiday season LHCb announced it was giving the particle physics community a highly anticipated holiday present : an updated measurement of the lepton flavor universality ratio R(K). Unfortunately when the wrapping paper was removed and the measurement revealed, the entire particle physics community let out a collective groan. It was not shiny new-physics-toy we had all hoped for, but another pair of standard-model-socks.
A disappointing present from LHCb, their recent measurement of R(K) (black points and error bars) showed very good agreement with the standard model prediction (red line).
The particle physics community is by now very used to standard-model-socks, receiving hundreds of pairs each year from various experiments all over the world. But this time there had be reasons to hope for more. Previous measurements of R(K) from LHCb had been showing evidence of a violation one of the standard model’s predictions (lepton flavor universality), making this triumph of the standard model sting much worse than most.
R(K) is the ratio of how often a B-meson (a bound state of a b-quark) decays into final states with a kaon (a bound state of an s-quark) plus two electrons vs final states with a kaon plus two muons. In the standard model there is a (somewhat mysterious) principle called lepton flavor universality which means that muons are just heavier versions of electrons. This principle implies B-mesons decays should produce electrons and muons equally and R(K) should be one.
But previous measurements from LHCb had found R(K) to be less than one, with around 3σ of statistical evidence. Other LHCb measurements of B-mesons decays had also been showing similar hints of lepton flavor universality violation. This consistent pattern of deviations had not yet reached the significance required to claim a discovery. But it had led a good amount of physicists to become #cautiouslyexcited that there may be a new particle around, possibly interacting preferentially with muons and b-quarks, that was causing the deviation. Several hundred papers were written outlining possibilities of what particles could cause these deviations, checking whether their existence was constrained by other measurements, and suggesting additional measurements and experiments that could rule out or discover the various possibilities.
Feynman diagrams showing the decay of a b quark into a strange quark and two leptons in the Standard Model (top). Two scenarios of new particles which could alter how often such an interaction occurs are shown in the bottom row: a new gauge boson (bottom left) and a leptoquark (bottom right).
This had all led to a considerable amount of anticipation for these updated results from LHCb. They were slated to be their final word on the anomaly using their full dataset collected during LHC’s 2nd running period of 2016-2018. Unfortunately what LHCb had discovered in this latest analysis was that they had made a mistake in their previous measurements.
There were additional backgrounds in their electron signal region which had not been previously accounted for. These backgrounds came from decays of B-mesons into pions or kaons which can be mistakenly identified as electrons. Backgrounds from mis-identification are always difficult to model with simulation, and because they are also coming from decays of B-mesons they produce similar peaks in their data as the sought after signal. Both these factors combined to make it hard to spot they were missing. Without accounting for these backgrounds it made it seem like there was more electron signal being produced than expected, leading to R(K) being below one. In this latest measurement LHCb found a way to estimate these backgrounds using other parts of their data. Once they were accounted for, the measurements of R(K) no longer showed any deviations, all agreed with one within uncertainties.
Plots showing two of the signal regions of for the electron channel measurements. The previously unaccounted for backgrounds are shown in lime green and the measured signal contribution is shown in red. These backgrounds have a peak overlapping with that of the signal, making it hard to spot that they were missing.
It is important to mention here that data analysis in particle physics is hard. As we attempt to test the limits of the standard model we are often stretching the limits of our experimental capabilities and mistakes do happen. It is commendable that the LHCb collaboration was able to find this issue and correct the record for the rest of the community. Still, some may be a tad frustrated that the checks which were used to find these missing backgrounds were not done earlier given the high profile nature of these measurements (their previous result claimed ‘evidence’ of new physics and was published in Nature).
Though the R(K) anomaly has faded away, the related set of anomalies that were thought to be part of a coherent picture (including another leptonic branching ratio R(D) and an angular analysis of the same B meson decay in to muons) still remain for now. Though most of these additional anomalies involve significantly larger uncertainties on the Standard Model predictions than R(K) did, and are therefore less ‘clean’ indications of new physics.
Besides these ‘flavor anomalies’ other hints of new physics remain, including measurements of the muon’s magnetic moment, the measured mass of the W boson and others. Though certainly none of these are slam dunk, as they each causes for skepticism.
So as we begin 2023, with a great deal of fresh LHC data expected to be delivered, particle physicists once again begin our seemingly Sisyphean task : to find evidence physics beyond the standard model. We know its out there, but nature is under no obligation to make it easy for us.
Paper: Test of lepton universality in b→sℓ+ℓ− decays (arXiv link)
References: https://arxiv.org/abs/1712.07158 (CMS) and https://arxiv.org/abs/1907.05120 (ATLAS)
If you are looking for love at the Large Hadron Collider this Valentines Day, you won’t find a better eligible bachelor than the b-quark. The b-quark (also called the ‘beauty’ quark if you are feeling romantic, the ‘bottom’ quark if you are feeling crass, or a ‘beautiful bottom quark’ if you trying to weird people out) is the 2nd heaviest quark behind the top quark. It hangs out with a cool crowd, as it is the Higgs’s favorite decay and the top quark’s BFF; two particles we would all like to learn a bit more about.
Choose beauty this valentines day
No one wants a romantic partner who is boring, and can’t stand out from the crowd. Unfortunately when most quarks or gluons are produced at the LHC, they produce big sprays of particles called ‘jets’ that all look the same. That means even if the up quark was giving you butterflies, you wouldn’t be able to pick its jets out from those of strange quarks or down quarks, and no one wants to be pressured into dating a whole friend group. But beauty quarks can set themselves apart in a few ways. So if you are swiping through LHC data looking for love, try using these tips to find your b(ae).
Look for a partner whose not afraid of commitment and loves to travel. Beauty quarks live longer than all the other quarks (a full 1.5 picoseconds, sub-atomic love is unfortunately very fleeting) letting them explore their love of traveling (up to a centimeter from the beamline, a great honeymoon spot I’ve heard) before decaying.
You want a lover who will bring you gifts, which you can hold on to even after they are gone. And when beauty quarks they, you won’t be in despair, but rather charmed with your new c-quark companion. And sometimes if they are really feeling the magic, they leave behind charged leptons when they go, so you will have something to remember them by.
The ‘profile photo’ of a beauty quark. You can see its traveled away from the crowd (the Primary Vertex, PV) and has started a cool new Secondary Vertex (SV) to hang out in.
But even with these standout characteristics, beauty can still be hard to find, as there are a lot of un-beautiful quarks in the sea you don’t want to get hung up on. There is more to beauty than meets the eye, and as you get to know them you will find that beauty quarks have even more subtle features that make them stick out from the rest. So if you are serious about finding love in 2022, its may be time to turn to the romantic innovation sweeping the nation: modern machine learning. Even if we would all love to spend many sleepless nights learning all about them, unfortunately these days it feels like the-scientist-she-tells-you-not-to-worry-about, neural networks, will always understand them a bit better. So join the great romantics of our time (CMS and ATLAS) in embracing the modern dating scene, and let the algorithms find the most beautiful quarks for you.
So if you looking for love this Valentines Day, look no further than the beauty quark. And if you area feeling hopeless, you can take inspiration from this decades-in-the-making love story from a few years ago: “Higgs Decay into Bottom Beauty Quarks Seen at Last”
A beautiful wedding photo that took decades to uncover, the Higgs decay in beauty quarks (red) was finally seen in 2018. Other, boring couples (dibosons), are shown in gray.
You might have heard that one of the big things we are looking for in collider experiments are ever elusive dark matter particles. But given that dark matter particles are expected to interact very rarely with regular matter, how would you know if you happened to make some in a collision? The so called ‘direct detection’ experiments have to operate giant multi-ton detectors in extremely low-background environments in order to be sensitive to an occasional dark matter interaction. In the noisy environment of a particle collider like the LHC, in which collisions producing sprays of particles happen every 25 nanoseconds, the extremely rare interaction of the dark matter with our detector is likely to be missed. But instead of finding dark matter by seeing it in our detector, we can instead find it by not seeing it. That may sound paradoxical, but its how most collider based searches for dark matter work.
The trick is based on every physicists favorite principle: the conservation of energy and momentum. We know that energy and momentum will be conserved in a collision, so if we know the initial momentum of the incoming particles, and measure everything that comes out, then any invisible particles produced will show up as an imbalance between the two. In a proton-proton collider like the LHC we don’t know the initial momentum of the particles along the beam axis, but we do that they were traveling along that axis. That means that the net momentum in the direction away from the beam axis (the ‘transverse’ direction) should be zero. So if we see a momentum imbalance going away from the beam axis, we know that there is some ‘invisible’ particle traveling in the opposite direction.
A sketch of what the signature of an invisible particle would like in a detector. Note this is a 2D cross section of the detector, with the beam axis traveling through the center of the diagram. There are two signals measured in the detector moving ‘up’ away from the beam pipe. Momentum conservation means there must have been some particle produced which is traveling ‘down’ and was not measured by the detector. Figure borrowed from here
We normally refer to the amount of transverse momentum imbalance in an event as its ‘missing momentum’. Any collisions in which an invisible particle was produced will have missing momentum as tell-tale sign. But while it is a very interesting signature, missing momentum can actually be very difficult to measure. That’s because in order to tell if there is anything missing, you have to accurately measure the momentum of every particle in the collision. Our detectors aren’t perfect, any particles we miss, or mis-measure the momentum of, will show up as a ‘fake’ missing energy signature.
Can you tell if there is any missing energy in this collision? Its not so easy… Figure borrowed from here
Even if you can measure the missing energy well, dark matter particles are not the only ones invisible to our detector. Neutrinos are notoriously difficult to detect and will not get picked up by our detectors, producing a ‘missing energy’ signature. This means that any search for new invisible particles, like dark matter, has to understand the background of neutrino production (often from the decay of a Z or W boson) very well. No one ever said finding the invisible would be easy!
However particle physicists have been studying these processes for a long time so we have gotten pretty good at measuring missing energy in our events and modeling the standard model backgrounds. Missing energy is a key tool that we use to search for dark matter, supersymmetry and other physics beyond the standard model.
Title : New physics and tau g−2 using LHC heavy ion collisions
Authors: Lydia Beresford and Jesse Liu
Reference: https://arxiv.org/abs/1908.05180
Since April, particle physics has been going crazy with excitement over the recent announcement of the muon g-2 measurement which may be our first laboratory hint of physics beyond the Standard Model. The paper with the new measurement has racked up over 100 citations in the last month. Most of these papers are theorists proposing various models to try an explain the (controversial) discrepancy between the measured value of the muon’s magnetic moment and the Standard Model prediction. The sheer number of papers shows there are many many models that can explain the anomaly. So if the discrepancy is real, we are going to need new measurements to whittle down the possibilities.
Given that the current deviation is in the magnetic moment of the muon, one very natural place to look next would be the magnetic moment of the tau lepton. The tau, like the muon, is a heavier cousin of the electron. It is the heaviest lepton, coming in at 1.78 GeV, around 17 times heavier than the muon. In many models of new physics that explain the muon anomaly the shift in the magnetic moment of a lepton is proportional to the mass of the lepton squared. This would explain why we are a seeing a discrepancy in the muon’s magnetic moment and not the electron (though there is a actually currently a small hint of a deviation for the electron too). This means the tau should be 280 times more sensitive than the muon to the new particles in these models. The trouble is that the tau has a much shorter lifetime than the muon, decaying away in just 10-13 seconds. This means that the techniques used to measure the muons magnetic moment, based on magnetic storage rings, won’t work for taus.
Thats where this new paper comes in. It details a new technique to try and measure the tau’s magnetic moment using heavy ion collisions at the LHC. The technique is based on light-light collisions (previously covered on Particle Bites) where two nuclei emit photons that then interact to produce new particles. Though in classical electromagnetism light doesn’t interact with itself (the beam from two spotlights pass right through each other) at very high energies each photon can split into new particles, like a pair of tau leptons and then those particles can interact. Though the LHC normally collides protons, it also has runs colliding heavier nuclei like lead as well. Lead nuclei have more charge than protons so they emit high energy photons more often than protons and lead to more light-light collisions than protons.
A Feynman diagram showing an “ultraperipheral collision” (UPC) between two lead nuclei. Both lead nuclei emit a photon and those two photons interact to produce two tau leptons that then decay.
Light-light collisions which produce tau leptons provide a nice environment to study the interaction of the tau with the photon. A particles magnetic properties are determined by its interaction with photons so by studying these collisions you can measure the tau’s magnetic moment.
However studying this process is be easier said than done. These light-light collisions are “Ultra Peripheral” because the lead nuclei are not colliding head on, and so the taus produced generally don’t have a large amount of momentum away from the beamline. This can make them hard to reconstruct in detectors which have been designed to measure particles from head on collisions which typically have much more momentum. Taus can decay in several different ways, but always produce at least 1 neutrino which will not be detected by the LHC experiments further reducing the amount of detectable momentum and meaning some information about the collision will lost.
However one nice thing about these events is that they should be quite clean in the detector. Because the lead nuclei remain intact after emitting the photon, the taus won’t come along with the bunch of additional particles you often get in head on collisions. The level of background processes that could mimic this signal also seems to be relatively minimal. So if the experimental collaborations spend some effort in trying to optimize their reconstruction of low momentum taus, it seems very possible to perform a measurement like this in the near future at the LHC.
Precision of the measurements of the anomalous magnetic moment of different leptons. The current best measurement of the tau’s anomalous magnetic moment is the DELPHI one with blue error bars, electron and muon measurements are the first two bars and are much more precise than that of the tau so their error bars have to been inflated to be visible. The green bars show the projected sensitivity using this new technique with different amounts of data and projections for the systematic uncertainty. The orange bar shows the value of the tau magnetic moment in some BSM scenarios that are compatible with current data.
The authors of this paper estimate that such a measurement with a the currently available amount of lead-lead collision data would already supersede the previous best measurement of the taus anomalous magnetic moment and further improvements could go much farther. Though the measurement of the tau’s magnetic moment would still be far less precise than that of the muon and electron, it could still reveal deviations from the Standard Model in realistic models of new physics. So given the recent discrepancy with the muon, the tau will be an exciting place to look next!
In a previous post we wondered if (machine learning) algorithms can replace the entire simulation of detectors and reconstruction of particles. But meanwhile some experimentalists have gone one step further – and wondered if algorithms can design detectors.
Indeed, the MODE collaboration stands for Machine-learning Optimized Design of Experiments and in its first paper promises nothing less than that.
The idea here is that the choice of characteristics that an experiment can have is vast (think number of units, materials, geometry, dimensions and so on), but its ultimate goal can still be described by a single “utility function”. For instance, the precision of the measurement on specific data can be thought of as a utility function.
Then, the whole process that leads to obtaining that function can be decomposed into a number of conceptual blocks: normally there are incoming particles, which move through and interact with detectors, resulting in measurements; from them, the characteristics of the particles are reconstructed; these are eventually analyzed to get relevant useful quantities, the utility function among them. Ultimately, chaining together these blocks creates a pipeline that models the experiment from one end to the other.
Now, another central notion is differentiation or, rather, the ability to be differentiated; if all the components of this model are differentiable, then the gradient of the utility function can be calculated. This leads to the holy grail: finding its extreme values, i.e. optimize the experiment’s design as a function of its numerous components.
Before we see whether the components are indeed differentiable and how the gradient gets calculated, here is an example of this pipeline concept for a muon radiography detector.
Discovering a hidden space in the Great Pyramid by using muons. ( Financial Times)
Muons are not just the trendy star of particle physics (as of April 2021), but they also find application in scanning closed volumes and revealing details about the objects in them. And yes, the Great Pyramid has been muographed successfully.
In terms of the pipeline described above, a muon radiography device could be modeled in the following way: Muons from cosmic rays are generated in the form of 4-vectors. Those are fed to a fast-simulation of the scanned volume and the detector. The interactions of the particles with the materials and the resulting signals on the electronics are simulated. This output goes into a reconstruction module, which recreates muon tracks. From them, an information-extraction module calculates the density of the scanned material. It can also produce a loss function for the measurement, which here would be the target quantity.
This whole ritual is a standard process in experimental work, although the steps are usually quite separate from one another. In the MODE concept, however, not only are they linked together but also run iteratively. The optimization of the detector design proceeds in steps and in each of them the parameters of the device are changed in the simulation. This affects directly the detector module and indirectly the downstream modules of the pipeline. The loop of modification and validation can be constrained appropriately to keep everything within realistic values, and also to make the most important consideration of all enter the game – that is of course cost and the constraints that it brings along.
As mentioned above, the proposed optimization proceeds in steps by optimizing the parameters along the gradient of the utility function. The most famous incarnation of gradient-based optimization is gradient descent which is customarily used in neural networks. Gradient descent guides the network towards the minimum value of the error that it produces, through the possible “paths” of its parameters.
In the MODE proposal the optimization is achieved through automatic differentiation (AD), the latest word in the calculation of derivatives in computer programs. To shamefully paraphrase Wikipedia, AD exploits the fact that every computer program, no matter how complicated, executes a sequence of elementary arithmetic operations and functions. By applying the chain rule repeatedly to these operations, derivatives can be computed automatically, accurately and efficiently.
Also, something was mentioned above about whether the components of the pipeline are “indeed differentiable”. It turns out that one isn’t. This is the simulation of the processes during the passage of particles through the detector, which is stochastic by nature. However, machine learning can learn how to mimic it, take its place, and provide perfectly fine and differentiable modules. (The brave of heart can follow the link at the end to find out about local generative surrogates.)
This method of designing detectors might sound like a thought experiment on steroids. But the point of MODE is that it’s the realistic way to take full advantage of the current developments in computation. And maybe to feel like we have really entered the third century of particle experiments.
First of all, let us take care of the spoilers: no new particles or phenomena have been found… Having taken this concern away, let us focus on the important concept behind MUSiC.
ATLAS and CMS, the two largest experiments using collisions at the LHC, are known as “general purpose experiments” for a good reason. They were built to look at a wide variety of physical processes and, up to now, each has checked dozens of proposed theoretical extensions of the Standard Model, in addition to checking the Model itself. However, in almost all cases their searches rely on definite theory predictions and focus on very specific combinations of particles and their kinematic properties. In this way, the experiments may still be far from utilizing their full potential. But now an algorithm named MUSiC is here to help.
MUSiC takes all events recorded by CMS that comprise of clean-cut particles and compares them against the expectations from the Standard Model, untethering itself from narrow definitions for the search conditions.
We should clarify here that an “event” is the result of an individual proton-proton collision (among the many happening each time the proton bunches cross), consisting of a bouquet of particles. First of all, MUSiC needs to work with events with particles that are well-recognized by the experiment’s detectors, to cut down on uncertainty. It must also use particles that are well-modeled, because it will rely on the comparison of data to simulation and, so, wants to be sure about the accuracy of the latter.
Display of an event with two muons at CMS. (Source: CMS experiment)
All this boils down to working with events with combinations of specific, but several, particles: electrons, muons, photons, hadronic jets from light-flavour (=up, down, strange) quarks or gluons and from bottom quarks, and deficits in the total transverse momentum (typically the signature of the uncatchable neutrinos or perhaps of unknown exotic particles). And to make things even more clean-cut, it keeps only events that include either an electron or a muon, both being well-understood characters.
These particles’ combinations result in hundreds of different “final states” caught by the detectors. However, they all correspond to only a dozen combos of particles created in the collisions according to the Standard Model, before some of them decay to lighter ones. For them, we know and simulate pretty well what we expect the experiment to measure.
MUSiC proceeded by comparing three kinematic quantities of these final states, as measured by CMS during the year 2016, to their simulated values. The three quantities of interest are the combined mass, combined transverse momentum and combined missing transverse momentum. It’s in their distributions that new particles would most probably show up, regardless of which theoretical model they follow. The range of values covered is pretty wide. All in all, the method extends the kinematic reach of usual searches, as it also does with the collection of final states.
An example distribution from MUSiC: Transverse mass for the final state comprising of one muon and missing transverse momentum. Color histograms: Simulated Standard Model processes. Red line: Signal from a hypothetical W’ boson with mass of 3TeV. (Source: paper)
So the kinematic distributions are checked against the simulated expectations in an automatized way, with MUSiC looking for every physicist’s dream: deviations. Any deviation from the simulation, meaning either fewer or more recorded events, is quantified by getting a probability value. This probability is calculated by also taking into account the much dreaded “look elsewhere effect”. (Which comes from the fact that, statistically, in a large number of distributions a random fluctuation that will mimic a genuine deviation is bound to appear sooner or later.)
When all’s said and done the collection of probabilities is overviewed. The MUSiC protocol says that any significant deviation will be scrutinized with more traditional methods – only that this need never actually arose in the 2016 data: all the data played along with the Standard Model, in all 1,069 examined final states and their kinematic ranges.
For the record, the largest deviation was spotted in the final state comprising three electrons, two generic hadronic jets and one jet coming from a bottom quark. Seven events were counted whereas the simulation gave 2.7±1.8 events (mostly coming from the production of a top plus an anti-top quark plus an intermediate vector boson from the collision; the fractional values are due to extrapolating to the amount of collected data). This excess was not seen in other related final states, “related” in that they also either include the same particles or have one less. Everything pointed to a fluctuation and the case was closed.
However, the goal of MUSiC was not strictly to find something new, but rather to demonstrate a method for model un-specific searches with collisions data. The mission seems to be accomplished, with CMS becoming even more general-purpose.