Paper Title: Observation of structure in the -pair mass spectrum
Authors: LHCb Collaboration
Reference: https://arxiv.org/pdf/2006.16957.pdf
My (artistic) rendition of a tetraquark. The blue and orange balls represent charm and anticharm quarks with gluons connecting all of them.
The Announcement
The LHCb collaboration reports a 5-sigma resonance at 6.9 GeV, consistent with predictions of a fully-charmed tetraquark state.
The Background
One of the ways quarks interact with each other is the strong nuclear force. This force is unlike the electroweak or gravitational forces in that the interaction strength increases with the separation between quarks, until it sharply falls off at roughly m. We say that the strong force is “confined” due to this sharp drop off. It is also dissimilar to the other forces in that the Strong force is non-perturbative. For perturbation theory to work well, the more complex a Feynman diagram becomes, the less it should contribute to the process. In the strong interaction though, each successive diagram contributes more than the previous one. Despite these challenges, physicists have still made sense organizing the zoo of quarks and bound states that come from particle collisions.
The quark () model [1,2] classifies hadrons into Mesons () and Baryons ( or ). It also allows for the existence of exotic hadrons like the tetraquark () or pentaquark (). The first evidence for an exotic hardon of this nature came in 2003 from the Belle Collaboration [1]. According to the LHCb collaboration, “all hadrons observed to date, including those of exotic nature, contain at most two heavy charm () or bottom () quarks, whereas many QCD-motivated phenomenological models also predict the existence of states consisting of four heavy quarks.” In this paper, the LHCb reports evidence of a state, the first fully charmed tetraquark state.
The Method
Perhaps the simplest way to form a fully charmed tetraquark state, from now on, is to form two charmonium states () which then themselves form a bound state. This search focuses on pairs of charmonium that are produced from two separate interactions, as opposed to resonant production through a single interaction. This is advantageous because “the distribution of any di- observable can be constructed using the kinematics from single production.” In other words, independent production reduces the amount of work it takes to construct observables.
Once is formed, the most useful decay it undergoes is into pairs of muons with about a 6% branching ratio [2]. To form candidates, the di-muon invariant mass must be between GeV. To form a di- candidate, the , all four muons are required to have originated from the same proton-proton collision point. This eliminates the possibility of associating two s from two different proton collisions.
The Findings
When the dust settles, the LHCb finds a resonance at MeV with a width of MeV. This resonance is just above twice the mass.
Recently the particle physics world has been abuzz with a new result from the XENON1T experiment who may have seen a revolutionary signal. XENON1T is one of the world’s most sensitive dark matter experiments. The experiment consists of a huge tank of Xenon placed deep underground in the Gran Sasso mine in Italy. It is a ‘direct-detection’ experiment, hunting for very rare signals of dark matter particles from space interacting with their detector. It was originally designed to look for WIMP’s, Weakly Interacting Massive Particles, who used to be everyone’s favorite candidate for dark matter. However, given recent null results by WIMP-hunting direct-detection experiments, and collider experiments at the LHC, physicists have started to broaden their dark matter horizons. Experiments like XENON1T, who were designed to look for heavy WIMP’s colliding off of Xenon nuclei have realized that they can also be very sensitive to much lighter particles by looking for electron recoils. New particles that are much lighter than traditional WIMP’s would not leave much of an impact on large Xenon nuclei, but they can leave a signal in the detector if they instead scatter off of the electrons around those nuclei. These electron recoils can be identified by the ionization and scintillation signals they leave in the detector, allowing them to be distinguished from nuclear recoils.
In this recent result, the XENON1T collaboration searched for these electron recoils in the energy range of 1-200 keV with unprecedented sensitivity. Their extraordinary sensitivity is due to its exquisite control over backgrounds and extremely low energy threshold for detection. Rather than just being impressed, what has gotten many physicists excited is that the latest data shows an excess of events above expected backgrounds in the 1-7 keV region. The statistical significance of the excess is 3.5 sigma, which in particle physics is enough to claim ‘evidence’ of an anomaly but short of the typical 5-sigma required to claim discovery.
The XENON1T data that has caused recent excitement. The ‘excess’ is the spike in the data (black points) above the background model (red line) in the 1-7 keV region. The significance of the excess is around 3.5 sigma.
So what might this excess mean? The first, and least fun answer, is nothing. 3.5 sigma is not enough evidence to claim discovery, and those well versed in particle physics history know that there have been numerous excesses with similar significances have faded away with more data. Still it is definitely an intriguing signal, and worthy of further investigation.
The pessimistic explanation is that it is due to some systematic effect or background not yet modeled by the XENON1T collaboration. Many have pointed out that one should be skeptical of signals that appear right at the edge of an experiments energy detection threshold. The so called ‘efficiency turn on’, the function that describes how well an experiment can reconstruct signals right at the edge of detection, can be difficult to model. However, there are good reasons to believe this is not the case here. First of all the events of interest are actually located in the flat part of their efficiency curve (note the background line is flat below the excess), and the excess rises above this flat background. So to explain this excess their efficiency would have to somehow be better at low energies than high energies, which seems very unlikely. Or there would have to be a very strange unaccounted for bias where some higher energy events were mis-reconstructed at lower energies. These explanations seem even more implausible given that the collaboration performed an electron reconstruction calibration using the radioactive decays of Radon-220 over exactly this energy range and were able to model the turn on and detection efficiency very well.
Results of a calibration done to radioactive decays of Radon-220. One can see that data in the efficiency turn on (right around 2 keV) is modeled quite well and no excesses are seen.
However the possibility of a novel Standard Model background is much more plausible. The XENON collaboration raises the possibility that the excess is due to a previously unobserved background from tritium β-decays. Tritium decays to Helium-3 and an electron and a neutrino with a half-life of around 12 years. The energy released in this decay is 18.6 keV, giving the electron having an average energy of a few keV. The expected energy spectrum of this decay matches the observed excess quite well. Additionally, the amount of contamination needed to explain the signal is exceedingly small. Around 100 parts-per-billion of H2 would lead to enough tritium to explain the signal, which translates to just 3 tritium atoms per kilogram of liquid Xenon. The collaboration tries their best to investigate this possibility, but they neither rule out or confirm such a small amount of tritium contamination. However, other similar contaminants, like diatomic oxygen have been confirmed to be below this level by 2 orders of magnitude, so it is not impossible that they were able to avoid this small amount of contamination.
So while many are placing their money on the tritium explanation, there is the exciting possibility remains that this is our first direct evidence of physics Beyond the Standard Model (BSM)! So if the signal really is a new particle or interaction what would it be? Currently it it is quite hard to pin down exactly based on the data. The analysis was specifically searching for two signals that would have shown up in exactly this energy range: axions produced in the sun, and neutrinos produced in the sun interacting with electrons via a large (BSM) magnetic moment. Both of these models provide good fits to the signal shape, with the axion explanation being slightly preferred. However since this result has been released, many have pointed out that these models would actually be in conflict with constraints from astrophysical measurements. In particular, the axion model they searched for would have given stars an additional way to release energy, causing them to cool at a faster rate than in the Standard Model. The strength of interaction between axions and electrons needed to explain the XENON1T excess is incompatible with the observed rates of stellar cooling. There are similar astrophysical constraints on neutrino magnetic moments that also make it unlikely.
This has left door open for theorists to try to come up with new explanations for these excess events, or think of clever ways to alter existing models to avoid these constraints. And theorists are certainly seizing this opportunity! There are new explanations appearing on the arXiv every day, with no sign of stopping. In the roughly 2 weeks since the XENON1T announced their result and this post is being written, there have already been 50 follow up papers! Many of these explanations involve various models of dark matter with some additional twist, such as being heated up in the sun or being boosted to a higher energy in some other way.
A collage of different models trying to explain the XENON1T excess (center). Each plot is from a separate paper released in the first week and a half following the original announcement. Source
So while theorists are currently having their fun with this, the only way we will figure out the true cause of this this anomaly is with more data. The good news is that the XENON collaboration is already preparing for the XENONnT experiment that will serve as a follow to XENON1T. XENONnT will feature a larger active volume of Xenon and a lower background level, allowing them to potentially confirm this anomaly at the 5-sigma level with only a few months of data. If the excess persists, more data would also allow them to better determine the shape of the signal; allowing them to possibly distinguish between the tritium shape and a potential new physics explanation. If real, other liquid Xenon experiments like LUX and PandaX should also be able to independently confirm the signal in the near future. The next few years should be a very exciting time for these dark matter experiments so stay tuned!
It’s no secret that the face of particle physics lies in the collaboration of scientists all around the world – and for the first time a group of 170 physicists have come to a consensus on one of the most puzzling predictions of the Standard Model muon. The anomalous magnetic moment of the muon concerns the particle’s rotation, or precession, in the presence of a magnetic field. Recall that elementary particles, like the electron and muon, possess intrinsic angular momentum, called spin, and hence indeed behave like a little dipole “bar magnet” – consequently affected by an external magnetic field.
The “classical” version of such an effect comes straight from the Dirac equation, a quantum mechanical framework for relativistic spin-1/2 particles like the electron and muon. It is expressed in terms of the g-factor, where in the Dirac theory. However, more accurate predictions, to compare to with experiment, require more extended calculations in the framework of quantum field theory, with “loops” of virtual particles forming the quantum mechanical corrections. In such a case we of course find deviation from the classical value in what becomes the anomalous magnetic moment with
For the electron, the prediction coming from Quantum Electrodynamics (QED) is so accurate, it actually agrees with the experimental result up to 10 significant figures (side note: in fact, this is not the only thing that agrees very well with experiment from QED, see precision tests of QED).
Figure 1: a “one-loop” contribution to the magnetic dipole moment in the theory of Quantum Electrodynamics (QED)
The muon, however, isn’t so simple and actually gets rather messy. In the Standard Model it comes with three parts, QED, electroweak and hadronic contributions
Up until now, the accuracy of these calculations have been the subject of a number of collaborations around the world. The largest source (in fact, almost all) of the uncertainty actually comes from the smaller contributions to the magnetic moment, the hadronic part. It is so difficult to estimate that it actually requires input from experimental sources and lattice QCD methods. This review constitutes the most comprehensive report of both the data-driven and lattice methods for hadronic contributions to the muon’s magnetic moment.
Their final result, remains 3.7 standard deviations below the current experimental value, measured at Fermilab in Brookhaven National Laboratory. However the most exciting part about all this is the fact that Fermilab is on the brink of releasing a new measurement, with the uncertainties reduced by almost a factor of four compared to the last. And if they don’t agree then? We could be that much closer to confirmation of some new physics in one of the most interesting of places!
References and Further Reading:
1. The new internationally-collaborated calculation: The anomalous magnetic moment of the muon in the Standard model, https://arxiv.org/abs/2006.04822
This post is intended to give an overview of the motivation, purpose, and discovery of the charm quark.
The Problem
The conventional 3-quark (up, down, and strange) models of the weak interaction are inconsistent with weak selection rules. In particular, strangeness-changing processes as seen in neutral Kaon oscillation [1]. These processes should be smaller than the predictions obtained from the conventional 3-quark theory. There are two diagrams that contribute to neutral kaon oscillation [2].
Neutral Kaon Oscillation
In a 3-quark model, the fermion propagators can only be up quark propagators, they both give a positive contribution to the process, and it seems as though we are stuck with these oscillations. It would be nice if we could somehow suppress these diagrams.
Solution
Introduce another up-type quark and one new quantum number called “Charm,” designed to counteract the effects of “Strangeness” carried by the strange quark. With some insight from the future, we will call this new up-type quark the charm quark.
Now, in our 4-quark model (up, down, strange, and charm), we have up and charm quark propagators a cancellation can in-principle occur. First proposed by Glashow, Iliopoulos, and Maiani, this mechanism would later become known as the “GIM Mechanism” [3]. The result is a suppression of these processes which is exactly what we need to make the theory consistent with experiments.
Experimental Evidence
Amusingly, two different experiments reported the same resonance at nearly the same time. In 1974, both the Stanford Linear Accelerator [4] and the Brookhaven National Lab [5] both reported a resonance at 3.1 GeV. SLAC named this particle the , and Brookhaven named it the and thus the particle was born. It turns out that the resonance they detected was “Charmonium,” a bound state of .
References
[1] – Report on Long Lived K0. This paper experimentally confirms neutral Kaons oscillation.
[2] – Kaon Physics. This powerpoint contains the picture of neutral Kaon oscillation that I used.
It isn’t often I get to plug an important experiment in high-energy physics located within my own vast country so I thought I would take this opportunity to do just that. That’s right – the land of the kangaroo, meat-pie and infamously slow internet (68th in the world if I recall) has joined the hunt for the ever elusive dark matter particle.
By now you have probably heard that about 85% of the universe is all made out of stuff that is dark. Searching for this invisible matter has not been an easy task, however the main strategy has involved detections of faint signals of dark matter scattering off nuclei that constantly pass through the Earth unimpeded. Up until now, the main contenders for these dark matter direct detection experiments have been performed above the equator.
The SABRE (Sodium-iodide with Active Background REjection) collaboration plans to operate two detectors – one in my home-state of Victoria, Australia at SUPL (Stawell Underground Physics Laboratory) and another in the northern hemisphere at LNGS, Italy. The choice to run two experiments in seperate hemispheres has the goal of potentially removing systematic effects inherent in the seasonal rotation of the Earth. In particular – any of these seasonal effects should be opposite in phase, whilst the dark matter signal should remain the same. This actually takes us to a novel dark matter direct detection search method known as annual modulation, which has been added to the spotlight through the DAMA/LIBRA scintillation detector underground the Laboratori Nazionali del Gran Sasso in Italy.
Around the world, around the world
Figure 1: When the Earth rotates around the sun, relative to the Milky Way’s DM halo, it experiences a larger interaction when it moves “head-on” with the wind. Taken from arXiv:1209.3339.
The DAMA/LIBRA experiment superseded the DAMA/NaI experiment which observed the dark matter halo over a period of 7 annual cycles ranging from 1995 to 2002. The idea is quite simple really. Current theory suggests that the Milky Way galaxy is surrounded by a halo of dark matter with our solar system casually floating by experiencing some “flux” of particles that pass through us all year round. However, current and past theory (up to a point) also suggest the Earth does a full revolution around the sun in a year’s time. In fact, with respect to this dark matter “wind”, the Earth’s relative velocity would be added on its approach, occurring around the start of June and then subtracted on its recession, in December. When studying detector interactions with the DM particles, one would then expect the rates to be higher in the middle of the year and of course lower at the end – hence a modulation (annually). Up to here, annual modulation results would be quite suitably model-independent and so wouldn’t depend on your particular choice of DM particle – so long as it has some interaction with the detector.
The DAMA collaboration, having reported almost 14 years of annual modulation results in total, claim evidence for a picture quite consistent with what would be expected for a range of dark matter scenarios in the energy range of 2-6 keV. This however has long been in tension with the wider community of detection for WIMP dark matter. Those such as XENON (which incidentally is also located in the Gran Sasso mountains) and CDMS have reported no detection of dark matter in the same ranges as that which the DAMA collaboration claimed to have seen them. Although these employ quite different materials such as (you guessed it) liquid xenon in the case of XENON and cryogenically cooled semiconductors at CDMS.
Figure 2: Annual modulation results from DAMA. Could this be the presence of WIMP dark matter or some other seasonal effect? From the DAMA Collaboration.
Yes, there is also the COSINE-100 experiment, using the same materials as those in DAMA (that is, sodium iodide), based in South Korea. And yes, they also published a letter to Nature claiming their results to be in “severe tension” with those of the DAMA annual modulation signal – under the assumption of WIMP interactions that are spin-independent with the detector material. However, this does not totally rule out the observation of dark matter by DAMA – just the fact that it is very unlikely to correspond to the gold-standard WIMP in a standard halo scenario. According to the collaboration, it will certainly take years more data collection to know for sure. But that’s where SABRE comes in!
As above, so below
Before the arrival of SABRE’s twin detectors in both the northern and southern hemispheres, the first phase known as the PoP (Proof of Principle) must be performed to analyze the entire search strategy and evaluate the backgrounds present in the crystal structures. Certainly, another feature of SABRE is a crystal background rate quite below that of DAMA/LIBRA using ultra-radiopure sodium iodide crystals. With the estimated current background and 50 kg of detector material, it is expected that the DAMA/LIBRA signal should be able to be independently verified (or refuted) in a matter of 3 years.
If you asked me, there is something a little special about an experiment operating on the frontier of fundamental physics in a small regional Victorian town with a population just over 6000 known for an active gold mining community and the oldest running foot race in Australia. Of course, Stawell features just the right environment to shield the detector from the relentless bombardment of cosmic rays on the Earth’s surface – and that’s why it is located 1 km underground. In fact, radiation contamination is such a prevalent issue for these sensitive detectors that everything from the concrete to the metal bolts that go in them must first be tested – and all this at the same time as the mine is still being operated.
Now, not only is SABRE experiments running in both Australia and Italy, but they actually comprise a collaboration of physicists also from the UK and the USA. But most importantly (for me, anyway) – this is the southern hemisphere’s very first dark matter detector – a great milestone and a fantastic opportunity to put Aussies in the pilot’s seat to uncover one of nature’s biggest mysteries. But for now, crack open a cold one – footy’s almost on!
Figure 3: The SABRE collaboration operates internationally with detectors in the northern and southern hemispheres. Taken from GSSI.
In my previous post, we discussed the features of dark matter freeze-out. The freeze-out scenario is the standard production mechanism for dark matter. There is another closely related mechanism though, the freeze-in scenario. This mechanism achieves the same results as freeze-out, but in a different way. Here are the ingredients we need, and the steps to make dark matter according to the freeze-in recipe [1].
Ingredients
Standard Model particles that will serve as a thermal bath, we will call these “bath particles.”
Dark matter (DM).
A bath-DM coupling term in your Lagrangian.
Steps
Pre-heat your early universe to temperature T. This temperature should be much greater than the dark matter mass.
Add in your bath particles and allow them to reach thermal equilibrium. This will ensure that the bath has enough energy to produce DM once we begin the next step.
Starting at zero, increase the bath-DM coupling such that DM production is very slow. The goal is to produce the correct amount of dark matter after letting the universe cool. If the coupling is too small, we won’t produce enough. If the coupling is too high, we will end up making too much dark matter. We want to make just enough to match the observed amount today.
Slowly decrease the temperature of the universe while monitoring the DM production rate. This step is analogous to allowing the universe to expand. At temperatures lower than the dark matter mass, the bath no longer has enough energy to produce dark matter. At this point, the amount of dark matter has “frozen-in,” there are no other ways to produce more dark matter.
Allow your universe to cool to 3 Kelvin and enjoy. If all went well, we should have a universe at the present-day temperature, 3 Kelvin, with the correct density of dark matter, (0.2-0.6) GeV/cm^3 [2].
This process is schematically outlined in the figure below, adapted from [1].
Schematic comparison of the freeze-in (dashed) and freeze-out (solid) scenarios.
On the horizontal axis we have the ratio of dark matter mass to temperature. Earlier times are to the left and later times are to the right. On the vertical axis is the dark matter number-density per entropy-density. This quantity automatically scales the number-density to account for cooling effects as the universe expands. The solid black line is the amount of dark matter that remains in thermal equilibrium with the bath. For the freeze-out recipe, the universe started out with a large population of dark matter that was in thermal equilibrium with the bath. In the freeze-in recipe, the universe starts with little to no dark matter and it never reaches thermal equilibrium with the bath. The dashed (solid) colored lines are dark matter abundances in the freeze-in (out) scenarios. Observe that in the freeze-in scenario, the amount of dark matter increases as temperature decreases. In the freeze-out scenario, the amount of dark matter decreases as temperature decreases. Finally, the arrows indicate the effect of increasing the X-bath coupling. For freeze in, increasing this interaction leads to more dark matter but in freeze-out, increasing this coupling leads to less dark matter.
Physics often doesn’t delay our introduction to one of the most important concepts in history – symmetries (as I am sure many fellow physicists will agree). From the idea that “for every action there is an equal and opposite reaction” to the vacuum solutions of electric and magnetic fields from Maxwell’s equations, we often take such astounding universal principles for granted. For example, how many years after you first calculated the speed of a billiard ball using conservation of momentum did you realise that what you were doing was only valid because of the fundamental symmetrical structure of the laws of nature? And hence goes our life through physics education – we first begin from what we ‘see’ to understanding what the real mechanisms are that operate below the hood.
These days our understanding of symmetries and how they relate to the phenomena we observe have developed so comprehensively throughout the 20th century that physicists are now often concerned with the opposite approach – applying the fundamental mechanisms to determine where the gaps are between what they predict and what we observe.
So far one of these important symmetries has stood up the test of time with no observable violation so far being reported. This is the simultaneous transformation of charge conjugation (C), parity (P) and time reversal (T), or CPT for short. A ‘CPT-transformed’ universe would be like a mirror-image of our own, with all matter as antimatter and opposite momenta. the amazing thing is that under all these transformations, the laws of physics behave the exact same way. With such an exceptional result, we would want to be absolutely sure that all our experiments say the same thing, so that brings us the our current topic of discussion – antihydrogen.
Matter, but anti.
Figure 1: The Hydrogen atom and its nemesis – antihydrogen. Together they are: Light. Source: Berkeley Science Review
The trick with antimatter is to keep it as far away from normal matter as possible. Antimatter-matter pairs readily interact, releasing vast amounts of energy proportional to the mass of the particles involved. Hence it goes without saying that we can’t just keep them sealed up in Tupperware containers and store them next to aunty’s lasagne. But what if we start simple – gather together an antiproton and a single positron and voila, we have antihydrogen – the antimatter sibling to the most abundant element in nature. Well this is precisely what the international ALPHA collaboration at CERN has been concerned with, providing “slowed-down” antiprotons with positrons in a device known as a Penning trap. Just like hydrogen, the orbit of a positron around an antiproton behaves like a tiny magnet, a property known as an object’s magnetic moment. The difficulty however is in the complexity of external magnetic field required to ‘trap’ the neutral antihydrogen in space. Therefore not surprisingly, these are the atoms of very low kinetic energy (i.e. cold) that cannot overcome the weak effect of external magnetism.
There are plenty more details of how the ALPHA collaboration acquires antihydrogen for study. I’ll leave this up to a reference at the end. What I’ll focus on is what we can do with it and what it means for fundamental physics. In particular, one of the most intriguing predictions of the invariance of the laws of physics under charge, parity and time transformations is that antihydrogen should share many of the same properties as hydrogen. And not just the mass and magnetic moment, but also the fine structure (atomic transition frequencies). In fact, the most successful theory of the 20th century, quantum electrodynamics (QED), properly accomodating anti-electronic interactions, also predicts a foundational test for both matter and antimatter hydrogen – the splitting of the and energy levels (I’ll leave a reference to a refresher on this notation). This is of course known as the Nobel-Prize winning Lamb Shift in hydrogen, a feature of the interaction between the quantum fluctuations in the electromagnetic field and the orbiting electron.
I’m feelin’ hyperfine
Of course it is only very recently that atomic versions of antimatter have been able to be created and trapped, allowing researchers to uniquely study the foundations of QED (and hence modern physics itself) from the perspective of this mirror-reflected anti-world. Very recently, the ALPHA collaboration have been able to report the fine structure of antihydrogen up to the state using laser-induced optical excitations from the ground state and a strong external magnetic field. Undergraduates by now will have seen, at least even qualitatively, that increasing the strength of an external magnetic field on an atomic structure also increases the gaps in the energy levels, and hence frequencies of their transitions. Maybe a little less known is the splitting due to the interaction between the electron’s spin angular momentum and that of the nucleus. This additional structure is known as the hyperfine structure, and is readily calculable in hydrogen utilizing the 1/2-integer spins of the electron and proton.
Figure 2: The expected energy levels in the antimatter version of hydrogen, an antiproton with an orbiting positron. Increased splitting on the x-axis are shown as a function of external magnetic field strength, a phenomena well-known in hydrogen (and thus predicted in antihydrogen) as the Zeeman Effect. The hyperfine splitting, due to the interaction between the positron and antiproton spin alignment are also shown by the arrows in the kets, respectively.
From the predictions of QED, one would expect antihydrogen to show precisely this same structure. Amazingly (or perhaps exactly as one would expect?) the average measurement of the antihydrogen transition frequencies agree with those in hydrogen to 16 ppb (parts per billion) – an observation that solidly keeps CPT invariance in rule but also opens up a new world of precision measurement of modern foundational physics. Similarly, with consideration to the Zeeman and hyperfine interactions, the splitting between is found to be consistent with the CPT invariance of QED up to a level of 2 percent, and the identity of the Lamb shift () up to 11 percent. With advancements in antiproton production and laser inducement of energy transitions, such tests provide unprecedented insight into the structure of antihydrogen. The presence of an antiproton and more accurate spectroscopy may even help in answering the unsolved question in physics: the size of the proton!
Figure 3: Transition frequencies observed in antihydrogen for the 1S-2P states (with various spin polarizations) compared with the theoretical expectation in hydrogen. The error bars are shown to 1 standard deviation.
Interested about why the size of the proton seems like such a challenge to figure out? See how the structure of hydrogen can be used to calculate it: https://en.wikipedia.org/wiki/Proton_radius_puzzle
In the universe, today, there exists some non-zero amount of dark matter. How did it get here? Has this same amount always been here? Did it start out as more or less earlier in the universe? The so-called “freeze out” scenario is one explanation for how the amount of dark matter we see today came to be.
The freeze out scenario essentially says that there is some large amount of dark matter in the early universe that decreases to the amount we observe today. This early universe dark matter is in thermal equilibrum with the particle bath , meaning that whatever particle processes create and destroy dark matter, they happen at equal rates, , so that the net amount of dark matter is unchanged. We will take this as our “initial condition” and evolve it by letting the universe expand. For pedagogical reasons, we will name processes that create dark matter “production” processes, and processes that destroy dark matter “annihilation” processes.
Now that we’ve established our initial condition, a large amount of dark matter in thermal equilibrium with the particle bath, let us evolve it by letting the universe expand. As the universe expands, two things happen:
The energy scale of the particle bath decreases. The expansion of the universe also cools down the particle bath. At energy scales (temperatures) less than the dark matter mass, the production reaction becomes kinematically forbidden. This is because the initial bath particles simply don’t have enough energy to produce dark matter. The annihilation process though is unaffected, it only requires that dark matter find itself to annihilate. The net effect is that as the universe cools, dark matter production slows down and eventually stops.
Dark matter annihilations cease. Due to the expansion of the universe, dark matter particles become increasingly separated in space which makes it harder for them to find each other and annihilate. The result is that as the universe expands, dark matter annihilations eventually cease.
Putting all of this together, we obtain the following plot, adapted from The Early Universe by Kolb and Turner and color-coded by me.
Fig 1: Color – coded freeze out scenario. The solid line is the density of dark matter that remains in thermal equilibrium as the universe expands. The dashed lines represent the freeze out density. The red region corresponds to a time in the universe when the production and annihilation rate are equal. The purple region; a time when the production rate is smaller than the annihilation rate. The blue region; a time when the annihilation rate is overwhelmed by the expansion of the universe.
On the horizontal axis is the dark matter mass divided by temperature . It is often more useful to parametrize the evolution of the universe as a function of temperature rather than time, through the two are directly related.
On the vertical axis is the co-moving dark matter number density, which is the number of dark matter particles inside an expanding volume as opposed to a stationary volume. The comoving number density is useful because it accounts for the expansion of the universe.
The quantity is the rate at which dark matter annihilates. If the annihilation rate is small, then dark matter does not annihilate very often, and we are left with more. If we increase the annihilation rate, then dark matter annihilates more frequently, and we are ultimately left with less of it.
The solid black line is the comoving dark matter density that remains in thermal equilibrium, where the production and annihilation rates are equal. This line falls because as the universe cools, the production rate decreases.
The dashed lines are the “frozen out” dark matter densities that result from the cooling and expansion of the universe. The comvoing density flattens off because the universe is expanding faster than dark matter can annihilate with itself.
The red region represents the hot, early universe where the production and annihilation rates are equal. Recall that the net effect is the amount of dark matter remains constant, so the comoving density remains constant. As the universe begins to expand and cool, we transition into the purple region. This region is dominated by temperature effects, since as the universe cools the production rate begins to fall and so the amount of dark matter than can remain in thermal equilibrium also falls. Finally, we transition to the blue region, where expansion dominate. In this region, dark matter particles can no longer find each other and annihilations cease. The comoving density is said to have “frozen out” because i) the universe is not energetic enough to produce new dark matter and ii) the universe is expanding faster than dark matter can annihilate with itself. Thus, we are left with a non-zero amount of dark matter than persists as the universe continues to evolve in time.
References
[1] – This plot is figure 5.1 of Kolb and Turners book The Early Universe (ISBN: 978-0201626742). There are many other plots that communicate essentially the same information, but are much more cluttered.
[2] – Dark Matter Genesis. This is a PhD thesis that does a good job of summarizing the history of dark matter and explaining how the freeze out mechanism works.
Protons and neutrons at first glance seem like simple objects. They have well defined spin and electric charge, and we even know their quark compositions. Protons are composed of two up quarks and one down quark and for neutrons, two downs and one up. Further, if a proton is moving, it carries momentum, but how is this momentum distributed between its constituent quarks? In this post, we will see that most of the momentum of the proton is in fact not carried by its constituent quarks.
Before we start, we need to have a small discussion about isospin. This will let us immediately write down the results we need later. Isospin is a quantum number that in practice, allows us to package particles together. Protons and neutrons form an isospin doublet, which means they come in the same mathematical package. The proton is the isospin +1/2 component of this package, and the neutron is the isospin -1/2 component of this package. Similarly, up quarks and down quarks form their own isospin doublet, and they come in their own package. In our experiment, if we are careful to choose which particles to scatter off of eachother, our calculations will permit us to exchange components of isospin packages everywhere instead of redoing calculations from scratch. This exchange is what I will call the “isospin trick.” It turns out that if compare electron-proton scattering to electron-neutron scattering allows us to use this trick:
Back to protons and neutrons. We know that protons and neutrons are composite particles, they themselves are made up of more fundamental objects. We need a way to “zoom into” these composite particles, to look inside them and we do this with the help of structure functions. Structure functions for the proton and neutron encode how electric charge and momentum are distributed between the constituents. We assign and to be the probability of finding an up or down quark with momentum fraction of the proton. Explicitly, these structure functions look like:
where the first line is the definition of a structure function. In this line, denotes quarks, and is the electric charge of quark . In the second line, we have written out explicitly the structure function for the proton , and invoked the isospin trick to immediately write down the structure function for the neutron in the third line. Observe that if we had attempted to write down following the definition in line 1, we would have gotten the same thing as the proton.
At this point we must turn to experiment to determine and . The plot we will examine [1] is figure 17.6 taken from section 17.4 of Peskin and Schroeder, An Introduction to Quantum Field Theory. Some data is omitted to illustrate a point.
The momentum distribution of the quarks inside the proton. Some data has been omitted for the purposes of this discussion. The full plot is provided at the end of this post.
This plot shows the momentum distribution of the up and down quarks inside a proton. On the horizontal axis is the momentum fraction and on the vertical axis is probability. The two curves represent the probability distribution of the up (u) and down (d) quarks inside the proton. Integrating these curves gives us the total percent of momentum stored in the up and down quarks which I will call uppercase and uppercase . We want to know know both and , so we need another equation to solve this system. Luckily we can repeat this experiment using neutrons instead of protons, obtain a similar set of curves, and integrate them to obtain the following system of equations:
Solving this system for and yields and . We immediately see that the total momentum carried by the up and down quarks is of the momentum of the proton. Said a different way, the three quarks that make up the proton, only carry half ot its momentum. One possible conclusion is that the proton has more “stuff” inside of it that is storing the remaining momentum. It turns out that this additional “stuff” are gluons, the mediators of the strong force. If we include gluons (and anti-quarks) in the momentum distribution, we can see that at low momentum fraction , most of the proton momentum is stored in gluons. Throughout this discussion, we have neglected anti-quarks because even at low momentum fractions, they are sub-dominant to gluons. The full plot as seen in Peskin and Schroeder is provided below for completeness.
References
[1] – Peskin and Schroeder, An Introduction to Quantum Field Theory, Section 17.4, figure 17.6.
[B] – Fundamentals in Nuclear Theory, Ch3. This is a more technical treatment of isospin, roughly at the level of undergraduate advanced quantum mechanics.
Article title: The ANITA Anomalous Events as Signatures of a Beyond Standard Model Particle and Supporting Observations from IceCube
Authors: Derek B. Fox, Steinn Sigurdsson, Sarah Shandera, Peter Mészáros, Kohta Murase, Miguel Mostafá, and Stephane Coutu
Reference: arXiv:1809.09615v1
Neutrinos have arguably made history for being nothing other than controversial. In fact from their very inception, their proposal by Wolfgang Pauli was described in his own words as “something no theorist should ever do”. Years on, as we established the role that neutrinos played in the processes of our sun, it was then discovered that it simply wasn’t providing enough of them. In the end the only option was to concede that neutrinos were more complicated than we ever thought, opening up a new area of study of ‘flavor oscillations’ with the consequence that they may in fact possess a small, non-zero mass – to this day yet to be explained.
On a more recent note, neutrinos have sneakily raised eyebrows with a number of other interesting anomalies. The OPERA collaboration, founded between CERN in Geneva, Switzerland and Gran Sasso, Italy, made international news with reports that their speeds exceeded the speed of light. Such an observation would certainly shatter the very foundations of modern physics and so was met with plenty of healthy skepticism. Alas it was eventually traced back to a faulty timing cable and all was right with the world again. However this has not been the last time that neutrinos have been involved in another controversial anomaly.
The NASA-involved Antarctic Impulsive Transient Antenna (ANITA) is an experiment designed to search for very, very energetic neutrinos originating from outer space. As the name also suggests, the experiment consists of a series of radio antennae contained in a balloon floating above the southern Antarctic ice. Very energetic neutrinos can in fact produce intense radio wave signals when they pass through the Earth and scatter off atoms in the Antarctic ice. This may sound strange, as neutrinos are typically referred to as ‘elusive’, however at incredibly high energies their probability of scattering increases dramatically – to the point where the Earth is ‘opaque’ to these neutrinos.
ANITA typically searches for the electromagnetic components of cosmic rays in the atmosphere, reflecting off the ice surface and subsequently inverting the phase of the radio wave. Alternatively, a small number of events can occur in the direction of the horizon, without reflecting off the ice and hence not inverting the waveform. However, physicists were surprised to find signals originating from below the ice, without phase inversion, in a direction much too steep to originate from the horizon.
Why is this a surprise you may ask? Well any particle present in the SM at these energies would have trouble traversing such a long distance throughout the Earth, measured in one of the observations with a chord length of 5700 km, whereas a neutrino would be expected to only survive a few hundred km. Such events would be expected to be mainly involving (tau neutrinos), since these have the potential to convert to a charged tau lepton shortly before arriving and hadronising into an air shower, which is simply not possible for electrons or muons which are absorbed by the ice in a much smaller distance. But even in the case of tau neutrinos, the probability of such an event occuring with the observed trajectory is very small (below one in a million), leading physicists to explore more exotic (and exciting) options.
A simple possibility is that the ultra-high energy neutrinos coming from space could interact within the Earth to produce a BSM (Beyond Standard Model) particle that passes through the Earth until it exits and decays back to an SM lepton and then hadronizes in a shower of particles. Such a situation is shown in Figure 1, where the BSM particle comes from the well-known and popular supersymmetric SM extension, known as the stauslepton.
Figure 1: An ultra-high energy neutrino interacting within the Earth to produce a beyond Standard Model particle before decaying back to a charged lepton and hadronizing, leaving a radio signal for ANITA. From “Tests of new physics scenarios at neutrino telescopes” talk by Bhavesh Chauhan.
In some popular supersymmetric extensions to the Standard Model, the stau slepton is typically the next-to-lightest supersymmetric particle (or NLSP) and can in fact be quite long-lived. In the presence of a nucleus, the stau may convert to the tau lepton and the LSP, which is typically the neutralino. In the paper titled above, the stau NLSP can exist within the Gauge-Mediated Supersymmetry Breaking Model (GMSB) and can be produced through ultra-high energy neutrino interactions with nucleons with a not-so-tiny branching ratio of . Of course the tension still remains for the direct observation of staus that can fit resonably within this scenario, but the prospects of observing effects of BSM physics without the efforts of expensive colliders.
But the attempts at new physics explanations don’t end there. There are some ideas that involve the decays of very heavy dark matter candidates in the galactic Milky-Way center. In a similar vein, another possibility comes form the well-motivated sterile neutrino – a BSM candidate to explain the small, non-zero mass of the neutrino. There are a number of explanations for a large flux of sterile neutrinos throughout the Earth, however the rate at which they interact with the Earth is much more suppressed than the light “active” neutrinos. It could be then hoped that they would make their passage to the ANITA detector after converting back to a tau lepton.
Anomalies like these come and go, however in any case, physicists remain interested in alternate pathways to new physics – or even a motivation to search in a more specific region with collider technology. But collecting more data first always helps!

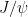




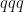


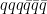



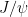


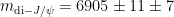
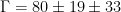





 in the Dirac theory. However, more accurate predictions, to compare to with experiment, require more extended calculations in the framework of quantum field theory, with “loops” of virtual particles forming the quantum mechanical corrections. In such a case we of course find deviation from the classical value in what becomes the anomalous magnetic moment with
in the Dirac theory. However, more accurate predictions, to compare to with experiment, require more extended calculations in the framework of quantum field theory, with “loops” of virtual particles forming the quantum mechanical corrections. In such a case we of course find deviation from the classical value in what becomes the anomalous magnetic moment with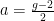


 remains 3.7 standard deviations below the current experimental value, measured at Fermilab in Brookhaven National Laboratory. However the most exciting part about all this is the fact that Fermilab is on the brink of releasing a new measurement, with the uncertainties reduced by almost a factor of four compared to the last. And if they don’t agree then? We could be that much closer to confirmation of some new physics in one of the most interesting of places!
remains 3.7 standard deviations below the current experimental value, measured at Fermilab in Brookhaven National Laboratory. However the most exciting part about all this is the fact that Fermilab is on the brink of releasing a new measurement, with the uncertainties reduced by almost a factor of four compared to the last. And if they don’t agree then? We could be that much closer to confirmation of some new physics in one of the most interesting of places!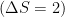 processes as seen in neutral Kaon oscillation
processes as seen in neutral Kaon oscillation 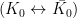 [1]. These processes should be smaller than the predictions obtained from the conventional 3-quark theory. There are two diagrams that contribute to neutral kaon oscillation [2].
[1]. These processes should be smaller than the predictions obtained from the conventional 3-quark theory. There are two diagrams that contribute to neutral kaon oscillation [2].
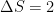 oscillations. It would be nice if we could somehow suppress these diagrams.
oscillations. It would be nice if we could somehow suppress these diagrams.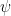 , and Brookhaven named it the
, and Brookhaven named it the 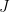 and thus the
and thus the  particle was born. It turns out that the resonance they detected was “Charmonium,” a bound state of
particle was born. It turns out that the resonance they detected was “Charmonium,” a bound state of  .
. particle.
particle.




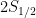 and
and 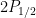 energy levels (I’ll leave a reference to a refresher on this notation). This is of course known as the Nobel-Prize winning Lamb Shift in hydrogen, a feature of the interaction between the quantum fluctuations in the electromagnetic field and the orbiting electron.
energy levels (I’ll leave a reference to a refresher on this notation). This is of course known as the Nobel-Prize winning Lamb Shift in hydrogen, a feature of the interaction between the quantum fluctuations in the electromagnetic field and the orbiting electron.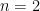 state using laser-induced optical excitations from the ground state and a strong external magnetic field. Undergraduates by now will have seen, at least even qualitatively, that increasing the strength of an external magnetic field on an atomic structure also increases the gaps in the energy levels, and hence frequencies of their transitions. Maybe a little less known is the splitting due to the interaction between the electron’s spin angular momentum and that of the nucleus. This additional structure is known as the hyperfine structure, and is readily calculable in hydrogen utilizing the 1/2-integer spins of the electron and proton.
state using laser-induced optical excitations from the ground state and a strong external magnetic field. Undergraduates by now will have seen, at least even qualitatively, that increasing the strength of an external magnetic field on an atomic structure also increases the gaps in the energy levels, and hence frequencies of their transitions. Maybe a little less known is the splitting due to the interaction between the electron’s spin angular momentum and that of the nucleus. This additional structure is known as the hyperfine structure, and is readily calculable in hydrogen utilizing the 1/2-integer spins of the electron and proton.
 is found to be consistent with the CPT invariance of QED up to a level of 2 percent, and the identity of the Lamb shift (
is found to be consistent with the CPT invariance of QED up to a level of 2 percent, and the identity of the Lamb shift (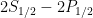 ) up to 11 percent. With advancements in antiproton production and laser inducement of energy transitions, such tests provide unprecedented insight into the structure of antihydrogen. The presence of an antiproton and more accurate spectroscopy may even help in answering the unsolved question in physics: the size of the proton!
) up to 11 percent. With advancements in antiproton production and laser inducement of energy transitions, such tests provide unprecedented insight into the structure of antihydrogen. The presence of an antiproton and more accurate spectroscopy may even help in answering the unsolved question in physics: the size of the proton!
 is in thermal equilibrum with the particle bath
is in thermal equilibrum with the particle bath  , meaning that whatever particle processes create and destroy dark matter, they happen at equal rates,
, meaning that whatever particle processes create and destroy dark matter, they happen at equal rates, 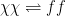 , so that the net amount of dark matter is unchanged. We will take this as our “initial condition” and evolve it by letting the universe expand. For pedagogical reasons, we will name processes that create dark matter
, so that the net amount of dark matter is unchanged. We will take this as our “initial condition” and evolve it by letting the universe expand. For pedagogical reasons, we will name processes that create dark matter  “production” processes, and processes that destroy dark matter
“production” processes, and processes that destroy dark matter  “annihilation” processes.
“annihilation” processes.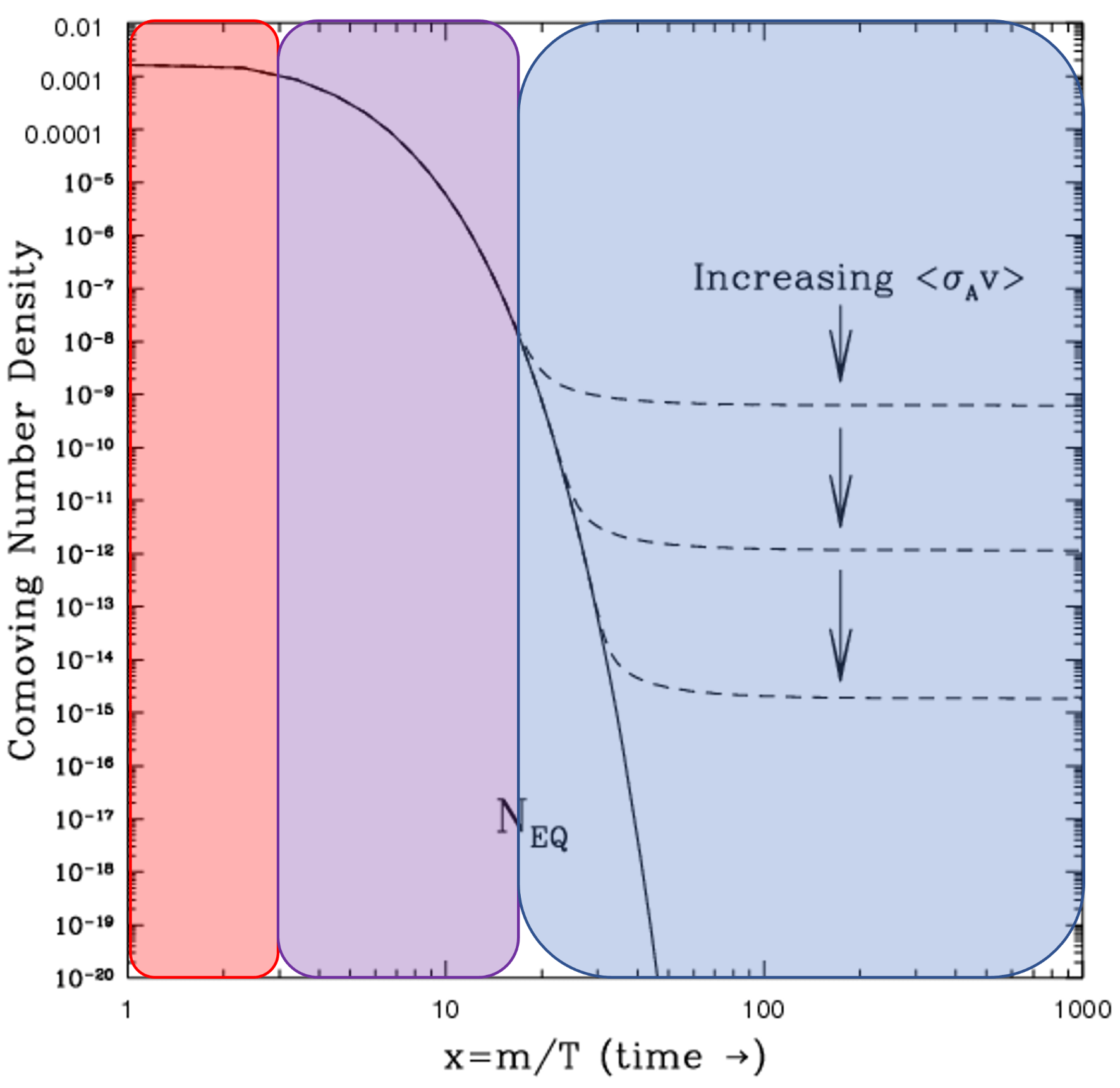
 . It is often more useful to parametrize the evolution of the universe as a function of temperature rather than time, through the two are directly related.
. It is often more useful to parametrize the evolution of the universe as a function of temperature rather than time, through the two are directly related. is the rate at which dark matter annihilates. If the annihilation rate is small, then dark matter does not annihilate very often, and we are left with more. If we increase the annihilation rate, then dark matter annihilates more frequently, and we are ultimately left with less of it.
is the rate at which dark matter annihilates. If the annihilation rate is small, then dark matter does not annihilate very often, and we are left with more. If we increase the annihilation rate, then dark matter annihilates more frequently, and we are ultimately left with less of it.
 . Structure functions for the proton and neutron encode how electric charge and momentum are distributed between the constituents. We assign
. Structure functions for the proton and neutron encode how electric charge and momentum are distributed between the constituents. We assign 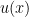 and
and 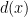 to be the probability of finding an up or down quark with momentum fraction
to be the probability of finding an up or down quark with momentum fraction  of the proton. Explicitly, these structure functions look like:
of the proton. Explicitly, these structure functions look like:
 is the electric charge of quark
is the electric charge of quark  , and invoked the isospin trick to immediately write down the structure function for the neutron
, and invoked the isospin trick to immediately write down the structure function for the neutron  in the third line. Observe that if we had attempted to write down
in the third line. Observe that if we had attempted to write down 
 and uppercase
and uppercase  . We want to know know both
. We want to know know both 
 and
and  . We immediately see that the total momentum carried by the up and down quarks is
. We immediately see that the total momentum carried by the up and down quarks is 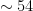 of the momentum of the proton. Said a different way, the three quarks that make up the proton, only carry half ot its momentum. One possible conclusion is that the proton has more “stuff” inside of it that is storing the remaining momentum. It turns out that this additional “stuff” are gluons, the mediators of the strong force. If we include gluons (and anti-quarks) in the momentum distribution, we can see that at low momentum fraction
of the momentum of the proton. Said a different way, the three quarks that make up the proton, only carry half ot its momentum. One possible conclusion is that the proton has more “stuff” inside of it that is storing the remaining momentum. It turns out that this additional “stuff” are gluons, the mediators of the strong force. If we include gluons (and anti-quarks) in the momentum distribution, we can see that at low momentum fraction 
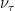 (tau neutrinos), since these have the potential to convert to a charged tau lepton shortly before arriving and hadronising into an air shower, which is simply not possible for electrons or muons which are absorbed by the ice in a much smaller distance. But even in the case of tau neutrinos, the probability of such an event occuring with the observed trajectory is very small (below one in a million), leading physicists to explore more exotic (and exciting) options.
(tau neutrinos), since these have the potential to convert to a charged tau lepton shortly before arriving and hadronising into an air shower, which is simply not possible for electrons or muons which are absorbed by the ice in a much smaller distance. But even in the case of tau neutrinos, the probability of such an event occuring with the observed trajectory is very small (below one in a million), leading physicists to explore more exotic (and exciting) options. .
.
 can exist within the Gauge-Mediated Supersymmetry Breaking Model (GMSB) and can be produced through ultra-high energy neutrino interactions with nucleons with a not-so-tiny branching ratio of
can exist within the Gauge-Mediated Supersymmetry Breaking Model (GMSB) and can be produced through ultra-high energy neutrino interactions with nucleons with a not-so-tiny branching ratio of  . Of course the tension still remains for the direct observation of staus that can fit resonably within this scenario, but the prospects of observing effects of BSM physics without the efforts of expensive colliders.
. Of course the tension still remains for the direct observation of staus that can fit resonably within this scenario, but the prospects of observing effects of BSM physics without the efforts of expensive colliders.