
Article Title: ABCDisCo: Automating the ABCD Method with Machine Learning
Authors: Gregor Kasieczka, Benjamin Nachman, Matthew D. Schwartz, David Shih
Reference: arxiv:2007.14400
When LHC experiments try to look for the signatures of new particles in their data they always apply a series of selection criteria to the recorded collisions. The selections pick out events that look similar to the sought after signal. Often they then compare the observed number of events passing these criteria to the number they would expect to be there from ‘background’ processes. If they see many more events in real data than the predicted background that is evidence of the sought after signal. Crucial to whole endeavor is being able to accurately estimate the number of events background processes would produce. Underestimate it and you may incorrectly claim evidence of a signal, overestimate it and you may miss the chance to find a highly sought after signal.
However it is not always so easy to estimate the expected number of background events. While LHC experiments do have high quality simulations of the Standard Model processes that produce these backgrounds they aren’t perfect. Particularly processes involving the strong force (aka Quantum Chromodynamics, QCD) are very difficult to simulate, and refining these simulations is an active area of research. Because of these deficiencies we don’t always trust background estimates based solely on these simulations, especially when applying very specific selection criteria.
Therefore experiments often employ ‘data-driven’ methods where they estimate the amount background events by using control regions in the data. One of the most widely used techniques is called the ABCD method.
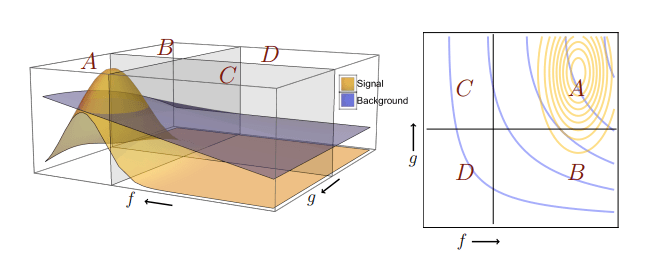
The ABCD method can applied if the selection of signal-like events involves two independent variables f and g. If one defines the ‘signal region’, A, (the part of the data in which we are looking for a signal) as having f and g each greater than some amount, then one can use the neighboring regions B, C, and D to estimate the amount of background in region A. If the number of signal events outside region A is small, the number of background events in region A can be estimated as N_A = N_B * (N_C/N_D).
In modern analyses often one of these selection requirements involves the score of a neural network trained to identify the sought after signal. Because neural networks are powerful learners one often has to be careful that they don’t accidentally learn about the other variable that will be used in the ABCD method, such as the mass of the signal particle. If two variables become correlated, a background estimate with the ABCD method will not be possible. This often means augmenting the neural network either during training or after the fact so that it is intentionally ‘de-correlated’ with respect to the other variable. While there are several known techniques to do this, it is still a tricky process and often good background estimates come with a trade off of reduced classification performance.
In this latest work the authors devise a way to have the neural networks help with the background estimate rather than hindering it. The idea is rather than training a single network to classify signal-like events, they simultaneously train two networks both trying to identify the signal. But during this training they use a groovy technique called ‘DisCo’ (short for Distance Correlation) to ensure that these two networks output is independent from each other. This forces the networks to learn to use independent information to identify the signal. This then allows these networks to be used in an ABCD background estimate quite easily.
The authors try out this new technique, dubbed ‘Double DisCo’, on several examples. They demonstrate they are able to have quality background estimates using the ABCD method while achieving great classification performance. They show that this method improves upon the previous state of the art technique of decorrelating a single network from a fixed variable like mass and using cuts on the mass and classifier to define the ABCD regions (called ‘Single Disco’ here).

While there have been many papers over the last few years about applying neural networks to classification tasks in high energy physics, not many have thought about how to use them to improve background estimates as well. Because of their importance, background estimates are often the most time consuming part of a search for new physics. So this technique is both interesting and immediately practical to searches done with LHC data. Hopefully it will be put to use in the near future!
Further Reading:
Quanta Magazine Article “How Artificial Intelligence Can Supercharge the Search for New Particles”
Recent ATLAS Summary on New Machine Learning Techniques “Machine learning qualitatively changes the search for new particles”
CERN Tutorial on “Background Estimation with the ABCD Method”
Summary of Paper of Previous Decorrelation Techniques used in ATLAS “Performance of mass-decorrelated jet substructure observables for hadronic two-body decay tagging in ATLAS“








 at no greater than
at no greater than  . In Peccei-Quinn symmetry,
. In Peccei-Quinn symmetry, 
 which is proportional to weak scale quantities) signify excluded portions of the parameter space. The remaining white space shows values of the axion decay constant and mass where the currently measured amount of baryon asymmetry could be generated. Source: https://arxiv.org/pdf/1910.02080.pdf
which is proportional to weak scale quantities) signify excluded portions of the parameter space. The remaining white space shows values of the axion decay constant and mass where the currently measured amount of baryon asymmetry could be generated. Source: https://arxiv.org/pdf/1910.02080.pdf














{kind=link}