
Authors: Chengcheng Han, Mihoko M. Nojiri, Michihisa Takeuchi, and Tsutomu T. Yanagida
Reference: arXiv:1609.09303v1 [hep-ph]
If you’ve been following the ongoing SUSY searches, you know that much of the phase space accessible at colliders like the LHC has been ruled out. Nevertheless, many phenomenologists are working diligently to develop alternative frameworks that maintain the compatibility of the Minimal Supersymmetric Standard Model (MSSM, one of the most compelling SUSY models) with recent experimental results. If evidence of SUSY is found at the LHC, it could help us start answering questions about naturalness, dark matter, gauge coupling unification, and other BSM questions, so it’s no wonder so many researchers are invested in keeping the SUSY search alive.
This particular paper discusses recent 13 TeV ATLAS results in the l+jets+ETmiss channel where an excess of up to 3.3σ above Standard Model expectations were seen in the initial 13TeV Run 2 dataset. Although CMS hasn’t reported any significant excess in this channel, both experiments see a moderate excess in the 0 lepton channel, so there’s some strong motivation for phenomenologists to explain these preliminary results as the presence of a new particle, namely a SUSY particle.
This ATLAS search is aimed at stop (the SUSY partner of the top quark) production where the stop then decays into a top and neutralino (a mixed state of the higgsino and gaugino, ie the SUSY partners of the Higgs and the gauge boson), and the top then decays to leptons. The stop is a particularly interesting SUSY particle, because it plays a critical role in the naturalness of SUSY models; most natural SUSY models predict a light stop and higgsino. The analysis group defined 7 (non exclusive) potential signal regions for this search, and excesses above 2σ were seen in 3 of them: DM_low, bC2x_diag, and SR1. The selection cuts for these regions are shown in Table 1. This paper discussed models to explain the DM_low excess of 3.3σ, but similar models could be used to explain the other excesses as well. The authors sought to create models which are compatible both with these results and the previous stop parameter limits set by ATLAS and CMS.

They first explored the two simplest one-step stop decays. Depending on what the Lightest Supersymmetric Particle (LSP) is, these decays can have different constraints, so they conducted a scan over the entire parameter space. There are two cases for this type of decay: (1) the LSP is a bino (SUSY partner of weak hypercharge boson) and the Next Lightest Super Symmetric Particle (NLSP) is the stop,leading to the simple decay shown in Figure 1a, or (2) the LSP is a higgsino which can be charged or neutral, with each possibility having different masses, which leads to the split decay shown in Figure 1b.

We can see in Figure 2 that most (or all in the case of the higgsino) of the preferred 2σ phase-space for these models are ruled out by existing constraints on stop production, so unfortunately these models aren’t particularly promising. Consequently, the authors designed an additional model essentially combing these two processes, where the LSP is a bino and the NLSP is a higgsino. This allows for both one step and two step decays, as shown in Figure 3. The results for this model are much more exciting; almost all of the preferred 2σ phase space exists outside of the existing constraints, as shown in Figure 4!


2 additional references are included in the Figure 4 plot. 3 benchmark models for different combinations of higgsino and stop masses are indicated with red crosses, and all of them fall in this allowed phase space. Furthermore, direct dark matter detection limits from the LUX experiment are shown as a dashed black line. The left side of this line has been excluded by LUX, so one of the considered benchmark models is not allowed. The second benchmark model falls near the exclusion line, so upcoming dark matter results will play an important role in telling us if this SUSY model can actually explain the excess!


So, SUSY hasn’t been found at the LHC, but its not dead yet! There are promising excesses in the current ATLAS dataset which are consistent with benchmark MSSM models with expected LSP candidates. We look forward to new data from the LHC and other experiments to tell us more!
References and further reading:
- Stephen P. Martin, “Supersymmetry primer” (arXiv:hep-ph/9709356)
- Sven Krippendorf, Fernando Quevedo, Oliver Schlotterer, “Cambridge Lectures on Supersymmetry and Extra Dimensions” (arXiv:1011.1491)
- John Ellis, “Supersymmetry, Dark Matter, and the LHC” (slides)

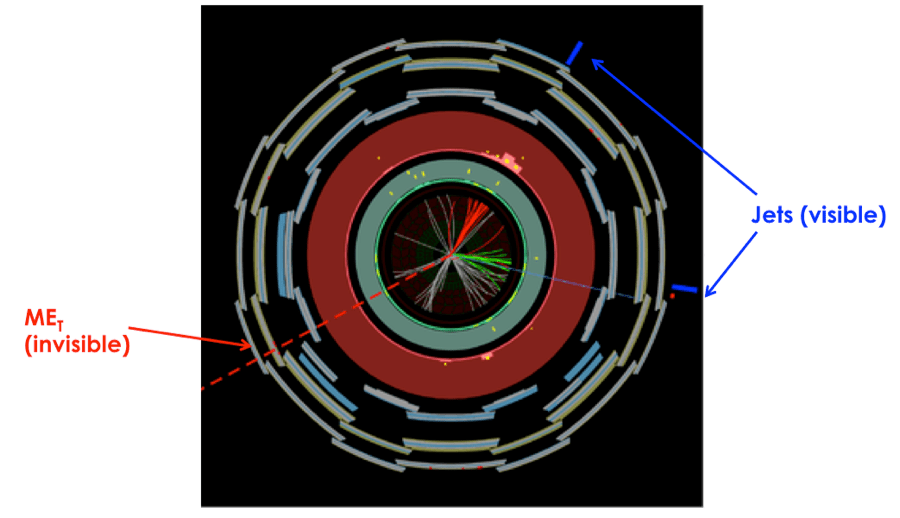




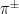 ) they see in the detector while theorists generally do calculations where jets have both charged and neutral particles (such as
) they see in the detector while theorists generally do calculations where jets have both charged and neutral particles (such as  , see my previous ParticleBites for a more general intro to jets). In order to compare predictions with experiment, someone is going to have to compromise. The concept of
, see my previous ParticleBites for a more general intro to jets). In order to compare predictions with experiment, someone is going to have to compromise. The concept of 
 multiplying this piece of whatever expression you’re dealing with. Luckily, it turns out that in QCD, this is largely all you need most of the time to make decent predictions. The tricky part is then turning a prediction about 1 particle splitting into 2 into a prediction about those particles splitting into 4 then 8 and so on, i.e. a fully hadronized and realistic event. For this, theorists generally employ hadronization “models” that are found by fitting to data or events simulated by Monte Carlo event generators. But how do you do this fitting? How can you properly separate physics into non-perturbative and perturbative pieces in a way that makes sense?
multiplying this piece of whatever expression you’re dealing with. Luckily, it turns out that in QCD, this is largely all you need most of the time to make decent predictions. The tricky part is then turning a prediction about 1 particle splitting into 2 into a prediction about those particles splitting into 4 then 8 and so on, i.e. a fully hadronized and realistic event. For this, theorists generally employ hadronization “models” that are found by fitting to data or events simulated by Monte Carlo event generators. But how do you do this fitting? How can you properly separate physics into non-perturbative and perturbative pieces in a way that makes sense? 

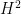 term represents the Higgs mass while the
term represents the Higgs mass while the  and
and 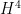 terms represent the Higgs self interactions we are interested in. In the Standard Model
terms represent the Higgs self interactions we are interested in. In the Standard Model  and
and 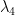 have a precise relation reflecting the underlying symmetries of the SM. By measuring interactions involving 3 and 4 Higgs bosons we can determine these parameters and therefore test directly this prediction of the SM. A deviation from from the Standard Model prediction would signal the presence of new physics which, needless to say, would send theorist into a drunk frenzy not seen since…
have a precise relation reflecting the underlying symmetries of the SM. By measuring interactions involving 3 and 4 Higgs bosons we can determine these parameters and therefore test directly this prediction of the SM. A deviation from from the Standard Model prediction would signal the presence of new physics which, needless to say, would send theorist into a drunk frenzy not seen since…
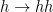 and
and  decays respectively (see Footnote 2). The
decays respectively (see Footnote 2). The 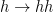 decays.
decays. decays (where
decays (where  is a photon), which i’ll focus on in todays post. If you recall
is a photon), which i’ll focus on in todays post. If you recall 
 and
and  . The number
. The number  measures the relative strength of cosmological perturbations with different wavelengths: if it is exactly equal to one, all perturbations have the same power, if it is smaller than one, the longer wavelengths have more power and if it is bigger than one, the smaller wavelengths have more power.
measures the relative strength of cosmological perturbations with different wavelengths: if it is exactly equal to one, all perturbations have the same power, if it is smaller than one, the longer wavelengths have more power and if it is bigger than one, the smaller wavelengths have more power. 
 .
. 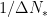 is small. Therefore, the expressions for
is small. Therefore, the expressions for  expansion, a given model may fall into one of these classes, but at the next-to-leading order it can belong to a different class. For instance, consider the popular inflationary model called Starobinsky inflation. Starobinsky inflation is non-perturbative at leading order but logarithmic at the next. Thus, the three classes are not enough to classify all models and you need to increase the number of classes if you consider the next-to-leading order. This is not a problem by itself, but it this means that one of the attractive features of these universality classes (“you only need three classes”) is not true. Due to these higher order terms, you need to introduce new hybrid classes. The number of universality classes increases even more if you go to even higher orders. Now you may argue that this is only a theoretical issue and that the lowest order is more than enough to describe the data. But this is not the case, as you can see in Fig.1.: you need at least to go to the next order to get accurate predictions (especially for future CMB experiments).
expansion, a given model may fall into one of these classes, but at the next-to-leading order it can belong to a different class. For instance, consider the popular inflationary model called Starobinsky inflation. Starobinsky inflation is non-perturbative at leading order but logarithmic at the next. Thus, the three classes are not enough to classify all models and you need to increase the number of classes if you consider the next-to-leading order. This is not a problem by itself, but it this means that one of the attractive features of these universality classes (“you only need three classes”) is not true. Due to these higher order terms, you need to introduce new hybrid classes. The number of universality classes increases even more if you go to even higher orders. Now you may argue that this is only a theoretical issue and that the lowest order is more than enough to describe the data. But this is not the case, as you can see in Fig.1.: you need at least to go to the next order to get accurate predictions (especially for future CMB experiments).
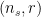 plane for various values of
plane for various values of ![\Delta N_* \in \left[ 50,60 \right]](https://s0.wp.com/latex.php?latex=%5CDelta+N_%2A+%5Cin+%5Cleft%5B+50%2C60+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) (or if you are slightly more conservative
(or if you are slightly more conservative ![\Delta N_* \in \left[ 40,70 \right]](https://s0.wp.com/latex.php?latex=%5CDelta+N_%2A+%5Cin+%5Cleft%5B+40%2C70+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) ). However, these values are only reasonable under specific conditions and depend sensitively on the period of reheating that follows inflation and the scale of inflation. For instance, one can even have
). However, these values are only reasonable under specific conditions and depend sensitively on the period of reheating that follows inflation and the scale of inflation. For instance, one can even have  in single-field inflation depending on the details of reheating. So for various models,
in single-field inflation depending on the details of reheating. So for various models, 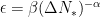
 and
and  . We may take a flat prior for these parameters. Now consider a particular model of inflation and reheating that falls within this universality class and is described by some parameters
. We may take a flat prior for these parameters. Now consider a particular model of inflation and reheating that falls within this universality class and is described by some parameters 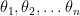 . For this model, the parameters
. For this model, the parameters